Think about it - your global, cloud-based application needs to be online and available for the business to run. Downtime is to be avoided like the plague. Perhaps you even have multiple cloud providers to span.
How do we create a database service layer that handles all kinds of failures?
Let's Talk About the Issues At Hand
Failures occur often, and in various places within the operational stack. Disk subsystems can fail, MySQL can crash due to an out of memory condition, or your cloud provider may lose an availability zone or even an entire region!
A major portion of creating resilience to failures is to craft an application with a holistic view of all required resources, including disk space, compute cycles, memory, network bandwidth, geo-scale latency and traffic routing.
What Do We Need, Exactly?
The goal is to provide a consistent set of data to a variety of servers located all over the world, all the while maintaining availability. A tall order, to be sure.
At the critical database layer, the ability to withstand a MySQL master server failure is called database High Availability (HA). Typically, the ability to withstand a site or region failure is called Disaster Recovery (DR).
We need both HA and DR.
How Do We Get That Done?
Tungsten Clustering is the most powerful way to keep your data online while withstanding failures at all layers of the operational stack.
Our Composite cluster has both local and global views of your database service layer which makes it ideal for geo-scaled deployments.
Composite clusters may be deployed in one of two possible modes of operation:
- Multimaster (active/active) - writes happen on the local write master and are distributed via replication to both local slaves and all remote site nodes. This topology requires the application to be active/active-aware, and MySQL's auto-increment feature to be configured appropriately. Reads may optionally directed to local slaves.
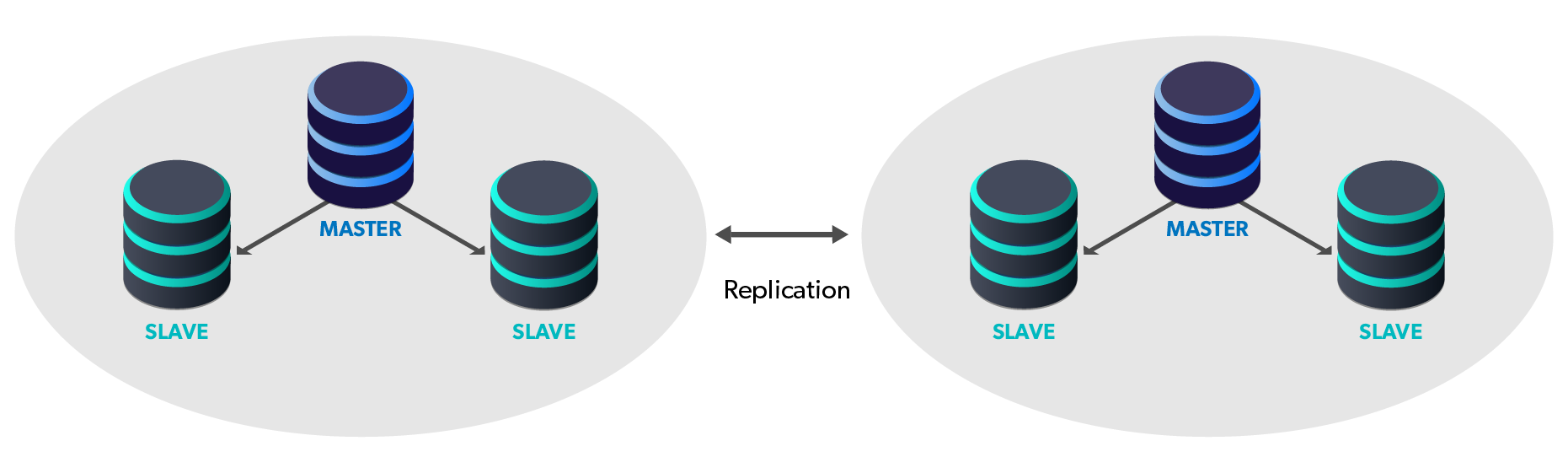
- Primary/DR (active/passive) - all writes happen on the single authoritative write master in the Primary site which are distributed via replication to all other local and remote nodes. Reads may optionally directed to local slaves.
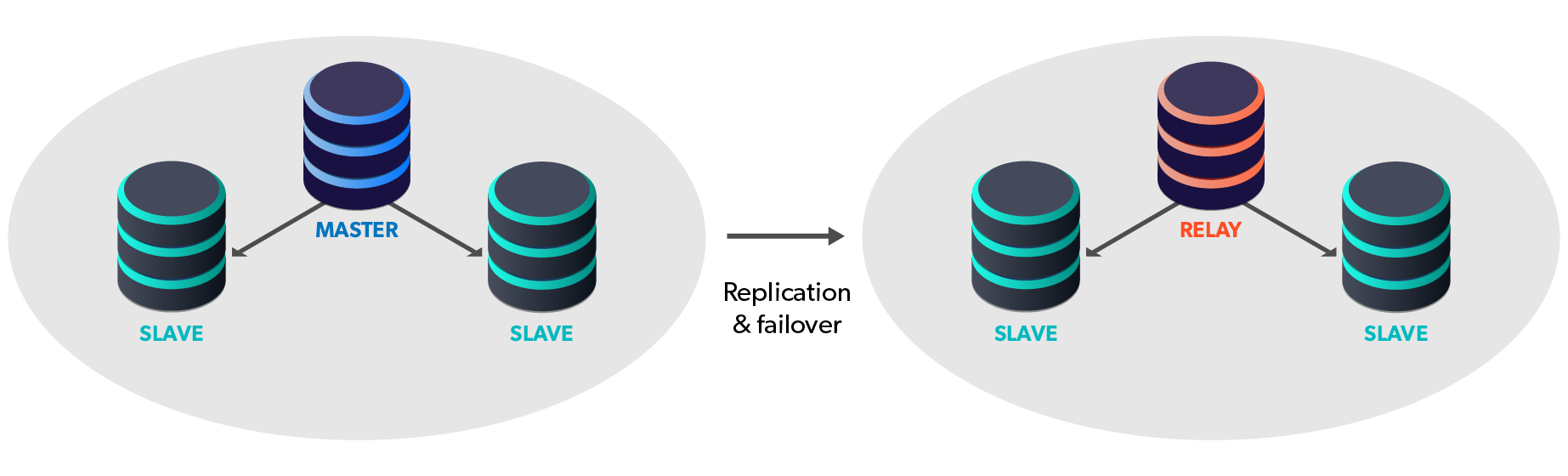
The Nitty-Gritty
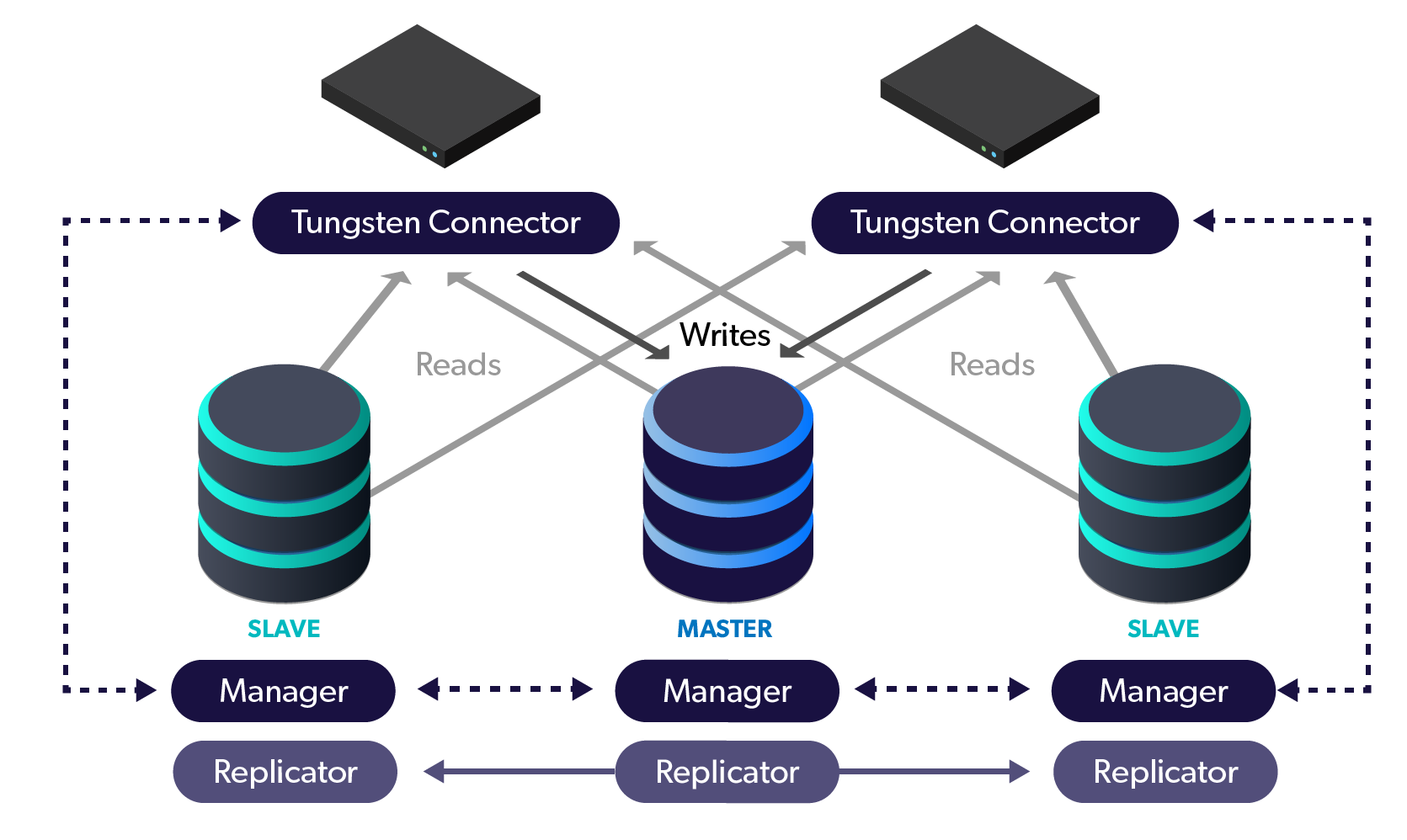
To accomplish our stated goal, one or more clusters of three or more nodes each are established per site/region (i.e. one node per availability zone in AWS) which are joined by both asynchronous database replication and management protocols.
The applications are reconfigured to use our cluster-aware proxy called the Connector. This intelligent proxy maintains cluster state via management signals and routes queries to the appropriate database node for writes and optionally, reads. This provides protection at the site level against hardware, OS and even entire AZ failures that could impact your master MySQL server.
For global deployments, all clusters become members of a Composite cluster, which allows the Connectors to be aware of remote site clusters. This powerful topology allows your application to write and read not only to and from site-local nodes, but also remote nodes. In the event of a master failure, the cluster automatically promotes the most up-to-date slave and routes the traffic to the new master. This provides availability in the unlikely event the entire database layer in a site or region goes down.
We Did It!
By deploying a Tungsten Cluster, we achieved the goal of providing both HA and DR for our database layer on a global scale.
This aligns perfectly with the Software-as-a-Service (SaaS) model where applications must have access to the data at all times.
Overall, Tungsten Clustering is the most flexible, performant global database layer available today - use it underlying your SaaS offering as a strong base upon which to grow your worldwide business!
Click here for more online information on Tungsten Clustering solutions
Want to learn more or run a POC? Contact us.

Comments
Add new comment