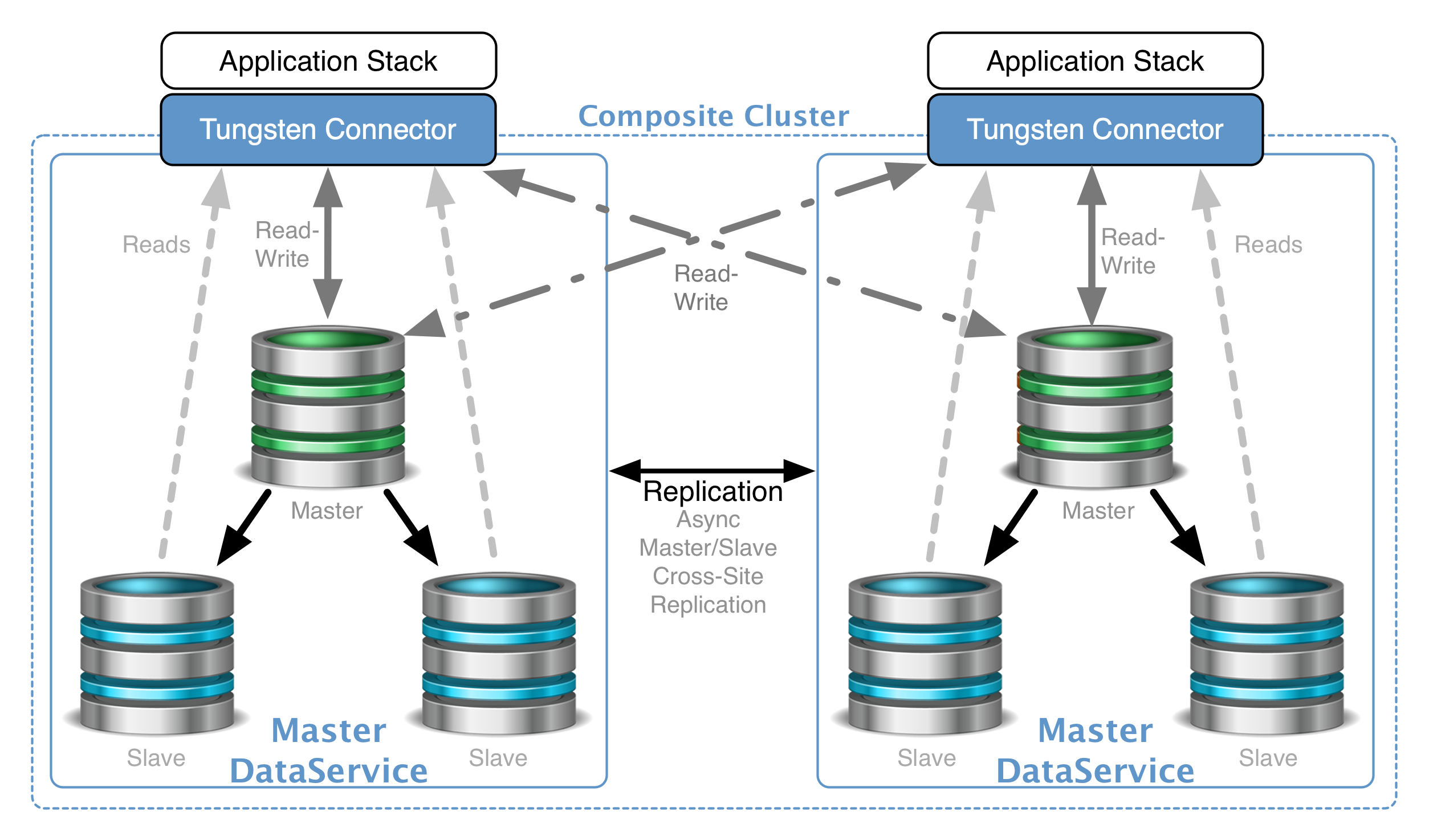
Overview
Clustering provides high availability and disaster recovery, along with the ability to read-scale both locally and globally. Some clusters even provide active/active capabilities, while others have a single master.
Real-time MySQL database replication is a must for clustering and other key business purposes, like reporting. There are a number of replication types available for MySQL, and some are even bundled into various solutions. When choosing a replication technology, it is paramount to understand just how the data moves from source to target. In this blog post, we will examine how asynchronous, synchronous, and "semi-synchronous" MySQL replication behave when used for clustering. Also, we will explore how MySQL replication type affects database performance and data availability.
Asynchronous Replication
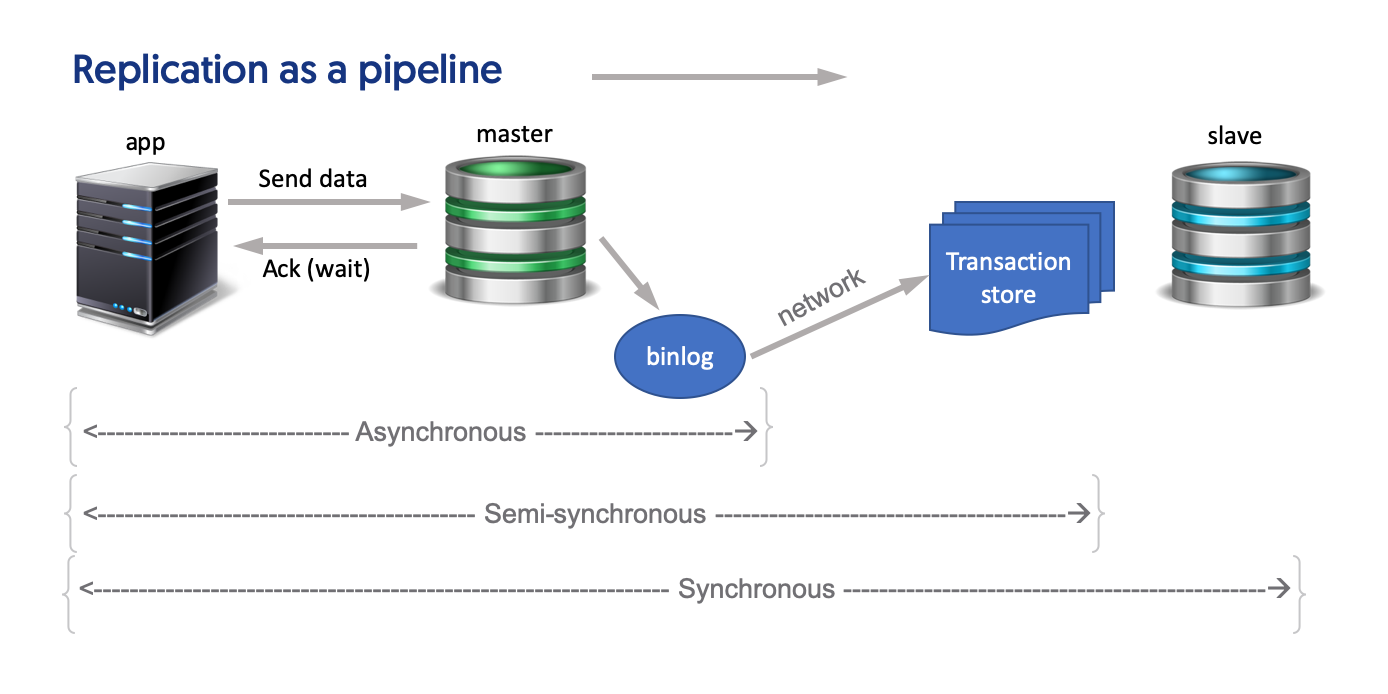
Asynchronous replication (async for short) is used by MySQL natively as well as by our own Tungsten Replicator. With async, all replication is decoupled from the database. Specifically, replication is a background process that reads events from the binary log on disk and makes those events available to the slaves upon request. There is no change to how the application works, and thus is quick and easy to implement. Also, async does not slow down the response from MySQL to the application.
With asynchronous replication, you have:
- The least impact to application performance of any replication type, because replication is handling database events separately in the background by reading the binary logs.
- The best (and really the only) choice for WAN replication because the application does not need to wait for confirmation from each slave before proceeding - this delay is prohibitive over long distances due to the simple physics of the speed of light creating delays in transit (Round-Trip-Time or RTT).
- The ability to deploy databases at geo-scale, serving applications that need high performance globally. Replication is de-coupled from your application, so slow WAN links do not imapct application performance.
- A chance of data lag on the replication slaves, which means that the slaves are not completely up-to-date with the master. In the event of a failure, there is a chance the newly-promoted slave would not have the same data as the master.
- The risk of data loss when promoting a slave to master per the above point. There are a number techniques to mitigate data loss which will be discussed in another blog post.
Synchronous Replication
Used by Galera and its variants, synchronous replication (sync for short) addresses the above data loss issues by guaranteeing that all transactions are committed on all nodes at database commit. Synchronous replication will wait until all nodes have the transaction committed before providing a response to the application, as opposed to asynchronous replication which occurs in the background after a commit to the master. With the sync method, you can be sure that if you commit a transaction, that transaction will be committed on every node.
With synchronous replication, you have:
- The most significant application lag of any type of replication, because your application must wait for all nodes in the cluster to commit the transaction too.
- Per above, it is complicated to implement over wide-area or slow networks, due to the almost prohibitive application lag, as it waits for transactions to be committed on remote databases.
- Transaction commit on all nodes, guaranteed.
- No slave data lag, as slaves are always up to date by definition.
- No chance of a data loss window in the event of a failover.
- Possibility to have multiple masters in a local cluster using a process called “certification”; certification will process transactions in order or, in the event of a conflict, raise an error.
Semi-Synchronous Replication
“Semi-Synchronous Replication,” used early on by Facebook and YouTube, attempts to merge the advantages of both asynchronous and semi-synchronous replication. With semi-synchronous replication (semi-sync for short), transactions are committed on the master, transferred to at least one slave node but NOT NECESSARILY committed. At this point, control is handed back to the application and commits to the slaves are handled in the background. Compared to synchronous replication, applications can potentially be more responsive since they receive control back sooner (though it is not as fast as async). Also, compared to async, there is less chance of data loss and potentially less replication lag.
With semi-synchronous replication, you have:
- Application response that is faster than synchronous replication, but slower than asynchronous replication
- The potential for a data loss window that is smaller than with asynchronous replication, but still larger than with synchronous replication.
- Configuration is more complex than with asynchronous replication, since it is not decoupled from the master database.
- A relatively new technology as compared to other replication methodologies. It remains to be seen if semi-sync will be a viable solution for production workloads.
Why does Tungsten Clustering choose Asynchronous Replication?
Tungsten Clustering uses the Tungsten Replicator, leveraging asynchronous replication, so that complex clusters can be deployed at geo scale without modifying or impacting applications or database servers. When deploying over wide area networks, asynchronous replication is the best and usually only option to protect application performance. Also, even over fast LAN’s, for write-intensive workloads, asynchronous replication is the best choice because the bottom-line impact to the application is minimized.
Look out for Part 2 of this blog, that will dive into how different MySQL replication types impact cluster behavior in day-to-day operations (such as failover, local and global replication breaks, zero downtime, maintenance updates, etc.).
For more information about Tungsten clusters, please visit www.continuent.com/products/tungsten-clustering
If you would like to speak with one of our team, please feel free to reach out here: https://www.continuent.com/contact

Comments
StephenAlani (not verified)
Mon, 09/30/2019 - 18:49
I like everything you post. You’ve done fantastic job
Add new comment