In this blog we’ll discuss the single most overlooked database clustering component that makes continuous database operations with DR easy, affordable, and manageable. This applies whether you’re a startup or large global company, or anything in between.
If you can tolerate downtime, you might not be interested in this blog.
But for many in industries -- such as SaaS, e-Commerce, Fintech, Gaming, IOT and Telco -- downtime can lead to a permanent dent in revenue and brand credibility; and for Public Safety, downtime could even risk human life. Generally, being able to trust that your database will be available and working 24/7/365 - provides some people with such great peace of mind, it helps them sleep at night.
Disaster Recovery came to the forefront with another major cloud outage the week of Thanksgiving 2020 (referencing the Washington Post because it’s owned by Jeff Bezos); this #awsoutage was reminiscent of numerous other outages among all the major cloud providers. For more on that, check out this article from Infoworld, discussing reasons multi-cloud is essential for resilience, and this article from CRN, discussing the biggest cloud outages in 2020 (so far).
...forego using any vendor services that might prevent your ability to move...pursue a data architecture that allows you to scale across data centers.
- Andrew C. Oliver, Strategic Developer,
source: Infoworld
You probably already know that continuous database operations necessitates geographic separation of operations: two (or more) of your own data centers in different cities, or hybrid-cloud (main system on-premises, DR in the cloud), multi-region or multi-cloud, or some other mix of infrastructure in different geographic locations.
What you might not be aware of is how easy it can be to deploy and manage a performant, available MySQL database layer with one of these complex topologies spread over WAN. Part of the reason has to do with one essential clustering component, “the orchestrator,” “the boss,” aka “the brains,” or “the manager.”
First of all, who am I? I’m a Customer Success Manager serving some long-time happy companies like ProductIP and Riot Games (check out Riot Games AWS:reInvent talk here), and I work closely with the Continuent engineers who develop infrastructure-agnostic (on-prem, hybrid-cloud, cloud, multi-cloud, etc.) MySQL, MariaDB, and Percona Server HA/DR/Geo-Scale solutions. We focus on business continuity and geo-scale solutions and best-in-class enterprise 24/7 support; and each year since 2004, we’ve safeguarded billions of dollars of combined revenue. The Continuent team remains at the forefront of business-continuity in the MySQL space through continuous innovation.
Continuent aims to be an objective, unbiased resource, so anyone who asks for help may get the best out of native MySQL, MariaDB or Percona Server. This is because we are a commercial supporter of the open-source ecosystem and a technology provider guaranteeing satisfaction through unlimited 24/7/365 access to highly experienced database experts in minutes’ notice.
First, let’s start with a basic definition of DR - from the VMware glossary:
Disaster recovery relies upon the replication of data and computer processing in an off-premises location not affected by the disaster. When servers go down because of a natural disaster, equipment failure, or cyber-attack, a business needs to recover lost data from a second location where the data is backed up.
For us, DR is about business continuity ie. fast and seamless failover to another site when the primary site experiences a failure. However, the cost of setting up and managing clusters of clusters spread over WAN can become exorbitant either in staff time or consulting.
For us, DR is about business continuity ie. fast and seamless failover to another site when the primary site experiences a failure.
And if your database clustering does not have some level of self-awareness and self-management built-in, you might find yourself constantly patching leaks instead of sailing; and if you go to the other extreme of using a DBaaS, you’re not the Captain - you’re part of someone else’s program, and all your eggs are in one basket - a basket that’s not agile across regions.
The good news is there are options and it doesn’t have to be complicated or cost-prohibitive. I encourage you as much as possible, with cloud vendors, consultancies, virtual DBA services, “managed” services, etc. trust...but verify! Ensure you’re getting the right technological solution first, so you can manage your services costs and save tons of time and headaches down the line. (Not to mention, the right technology means you don’t have to rely on people as much....and reduce risk of human error.)
Back to “the boss” or what makes the cluster act like a self-managing organization.
In Continuent Tungsten solutions the Tungsten Manager is in charge of all processes and operations internal to the cluster, whether you have one cluster or five in five different places - it is the brains that keep it all together and makes life easy by doing some of the thinking for us. The Manager is designed with intelligence so DevOps, DBA, SRE, IT and SysAdmin teams can spend their time focusing on other things. In case you’re interested in the weeds, some specific tasks of the Boss include:
- Monitoring the availability and replication status of each node (or database server) in the cluster.
- Sharing relevant information to the Tungsten Proxy so that it may change its data traffic rules as needed.
- Controlling all the different components in the cluster, including updating statuses, states and managing the replication process.
- Responding to different events within the cluster.
- Performing the necessary operations to keep the data service in an optimal working state.
- For example, during a change in the status of the cluster, the Manager informs the Proxy of the changes within the cluster and makes decisions, such as whether to promote a replica.
Tungsten Manager is great in all its glory; but it is the synergistic factor that makes it so valuable, especially when you have multiple clusters in different places for continuous operations with DR.
Tungsten Manager has been tested for an endless combination of edge cases along with the Tungsten Proxy and Tungsten Replicator for years, and always true to first-principles like an experienced, skillful people-manager, it ensures the other cluster components behave and perform optimally (ie. it keeps the Proxy routing database connections, and the Replicator moving data in real-time).
Speaking of great bosses, Continuent’s “Captain” (Founder and CEO), Eero Teerikorpi, just came out with a blog and video about MySQL DR Done Right! - so you can see a demo of how easy complex composite operations (or “clusters of multiple clusters”) can be.
But easy management aside, the deployment of the database layer is also simple when you account for the complexities of replicating data and routing traffic across different infrastructures or cloud providers. Fire up a database service anywhere in the world, and it’s automatically part of the greater self-managing cluster - because of the Manager keeping tabs on everything. If fact you can deploy a single global write composite service without making a single code change, without doing anything to your application layer; and, as stated by customers, it “just works,” “out-of-the-box.”
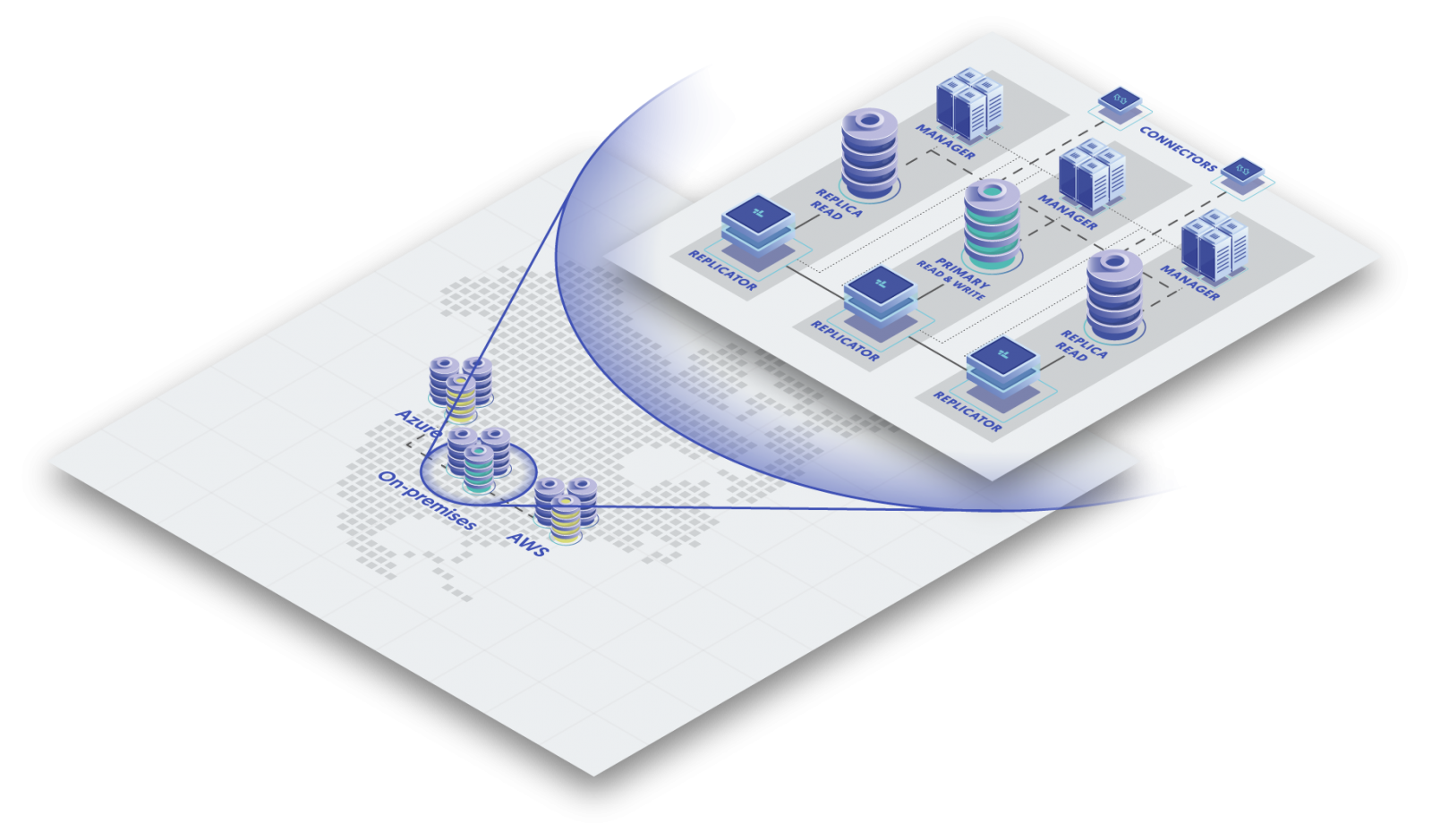
That’s one of the reasons customers love Tungsten - it’s a fully-integrated, mature and reliable MySQL clustering solution on the market. For a DR site (by definition, in a different location over WAN), you do not want to deal with performance hits or complexities of clustering operations that come with a cluster of clusters, such as manual or disjointed failover and failback (especially in the event of an emergency). You also want to easily do maintenance updates without impacting availability. And you do not want to wonder what’s going on underneath the hood, especially in Production environments - it just needs to work.
In conclusion, it’s when things go wrong, that you realize the value of a diligent cluster coordinator, or Manager, experienced with managing complex situations, and irreplaceable by even the most skillful human professional; let’s close out this blog with a case in point mention of the Amazon employee who made a typo and caused the notorious major 2017 AWS outage:
A massive AWS outage...disabled large chunks of the Internet, including sites such as Slack, Medium and Quora. That outage, which also hit the Northern Virginia region, was caused by human error, when an employee mistyped a command, taking down huge portions of the system and knocking out AWS’s core storage service.
Thanks for reading my blog. If you enjoyed this, please add me on Linkedin so we may stay connected, or feel free to reach out to us at Continuent to learn more about Tungsten and how we do things here!
Warm wishes for a safe holiday season!
Sara

Comments
Add new comment