Introduction
Tungsten Replicator is a core component within the Tungsten Clustering product and is responsible for the movement of data between nodes. However, this powerful tool can also be used as a standalone product and has a wealth of features, not least of all the ability to replicate from MySQL into a range of heterogeneous targets such as Oracle, PostgreSQL, Redshift, Mongo and more.
We were recently working with a customer that is using the Tungsten Machine Image (TMI) available in AWS and Google GCP, and wanted to explore one of the more complex topologies and features of the replicator, specifically the Fan-In topology to replicate from MySQL into Redshift.
In this short blog I will outline how we achieved this with the use of three very simple, but very powerful filters.
The Use Case
The customer has a multi-tenant environment, with each of their customers having their own schema within a single AWS Aurora source. Each schema contains a number of tables, but all identical in structure across the schemas.
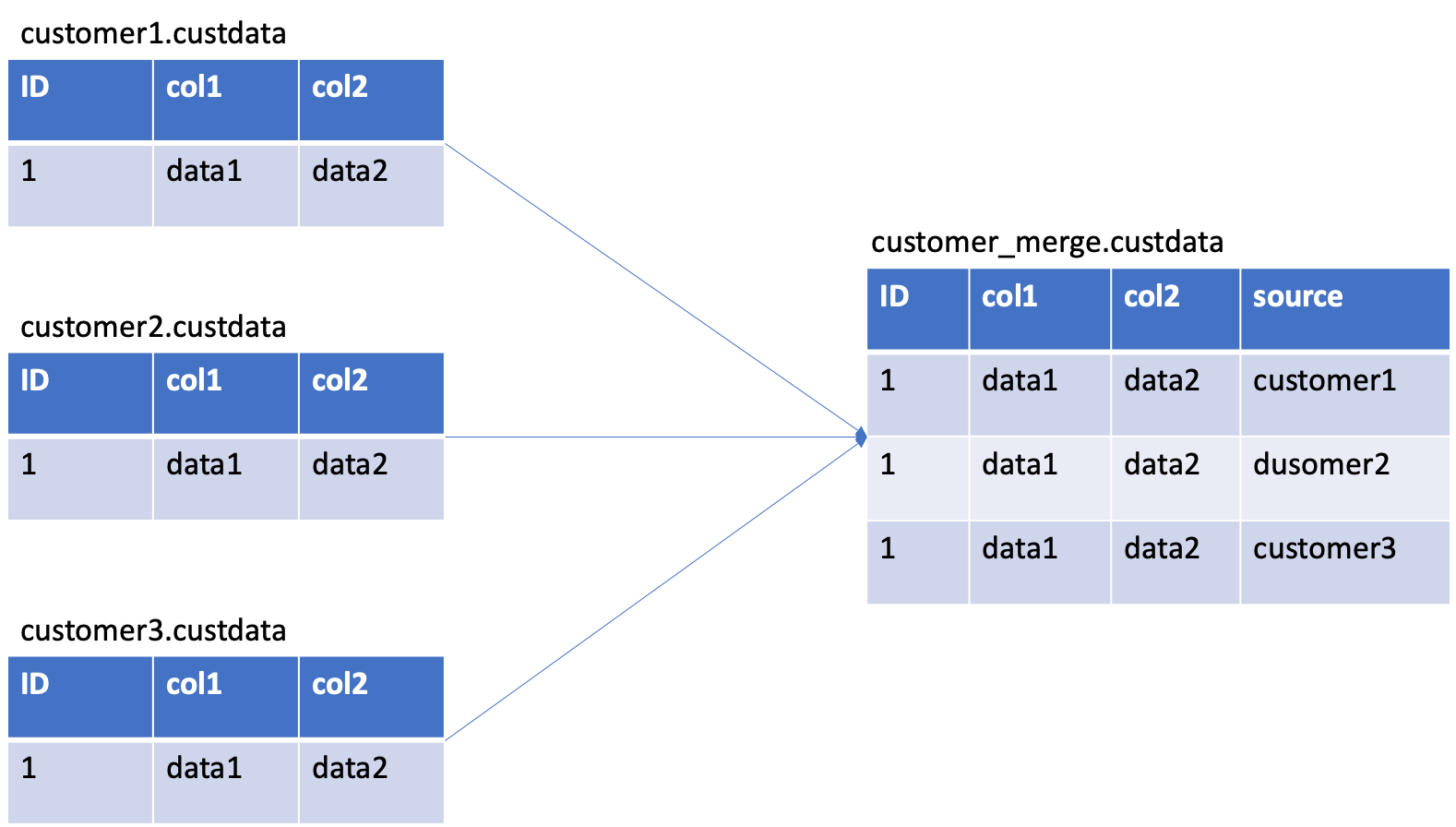
As part of their BI reporting requirements, they have a need to replicate this data into Redshift, however they want to merge and tag the data - so for example in the source, in each schema, they will have a table called `custdata`, for example, `customer1`.`custdata`, `customer2`.`custdata` and so on.
In Redshift they want one single schema, and one single `custdata` table that contains all the data merged from customer1, customer2… but they want each row tagged with the source schema that it came from, so they could cross reference each row of data to the specific source.
See the diagram below for a clearer representation of the requirements.
Currently, they are using a tool called Matillion, a powerful ETL tool that does work for them. However, the current process started with nightly syncs, but as the data grew this wasn’t sufficient, so they switched to hourly syncs, as the data has grown further this is also now becoming an issue with each hourly run almost not completing before the next begins. This is then having a knock-on effect to their downstream business needs.
Whilst Tungsten Replicator is not an ETL tool per se, the simple requirement in this use case is something we can achieve, and achieve well. Let’s explore the solution.
The Solution
In this instance, because all of the multi-tenant data is in a single Aurora source, the configuration is actually very simple.
To start, we configured a simple extractor against Aurora. Because we are writing out to a non-MySQL target (Redshift) we needed two extra options in the extractor:
enable-batch-master=true
enable-heterogeneous-service=trueThese options will ensure that we capture all of the relevant metadata we need and store this in the THL so that we can restructure the transactions to be compatible with the Redshift target.
Next, we implemented the replicate filter. In this case, we do this because the customer only wants to replicate two tables within each Schema. Filtering this on extraction will ensure the THL files are kept to a minimum size, and contain only the data we really need. This will then ensure the apply process is more efficient by not having to eliminate unwanted data. The settings for this are as follows:
svc-extractor-filters=replicate
property=replicator.filter.replicate.do=*.table1,*.table2
These two properties first enable the replicate filter, the second then provides the rules. In this example we are using the .do filter which tells the replicator to ignore everything except the objects specified in this rule. In this case, we are using the *.tablename format so that we match the table name only regardless of the schema.
A Redshift applier is a little more complicated. With a Redshift deployment we do not apply DML such as INSERT, UPDATE, DELETE via JDBC calls as these are inefficient in a column-store like redshift. This type of data store works best when loading large amounts of data in batches. So, for the redshift applier we load the data via batches of CSV which are in a defined format and loaded using the correct Redshift syntax. Our Tungsten Replicator White Paper explains the batch load process in greater detail.
The first step is to get the configuration for the applier setup, the following configuration is a typical example of the one used for this customer:
[defaults]
user=tungsten
install-directory=/opt/continuent
profile-script=~/.bash_profile
rest-api-admin-user=tungsten
rest-api-admin-password=secret
replicator-rest-api-address=0.0.0.0
disable-security-controls=true
[alpha]
role=slave
master=ext01
members=app01
replication-user=dbadmin
replication-password=Secret123
replication-host=redshift.endpoint.url
replication-port=5439
redshift_dbname=demo
datasource-type=redshift
batch-enabled=true
batch-load-language=js
batch-load-template=redshift
svc-applier-filters=dropstatementdata,rowadddbname,rename
property=replicator.filter.rename.definitionsFile=/opt/continuent/share/rename.csv
property=replicator.filter.rowadddbname.fieldname=src_db
property=replicator.filter.rowadddbname.adddbhash=false
svc-applier-block-commit-size=25000
svc-applier-block-commit-interval=5sFor the customer, the key elements in this configuration are
svc-applier-filters=dropstatementdata,rowadddbname,rename
property=replicator.filter.rename.definitionsFile=/opt/continuent/share/rename.csv
property=replicator.filter.rowadddbname.fieldname=src_db
property=replicator.filter.rowadddbname.adddbhash=false
There are 3 filters in this configuration, the first, dropstatementdata, is required by default for all Redshift appliers, this will drop DDL statements such as CREATE TABLE as these cannot be translated in real-time and would cause the replicator to error if we attempted to write this into Redshift.
The second, rowaddbname, allows us to “modify” the THL by adding a new column of data to each row before we write it into Redshift. This filter has additional properties, and in this example we have the following:
property=replicator.filter.rowadddbname.fieldname=src_db
property=replicator.filter.rowadddbname.adddbhash=falseThe first is the column name we want to add, the second is disabling an additional hash column. The result of this filter is that the additional column will contain the schema name from which the source data originated.
The final filter, rename, allows us to remap and merge the data. This filter has an additional csv configuration file that contains the mappings. This file looks like the following:
customer1,*,*,customer_merge,-,-
customer2,*,*,customer_merge,-,-
customer3,*,*,customer_merge,-,-The format of this file is as follows:
sourceschema,sourcetable,sourcecolumn,targetschema,targettable,targetcolumn
The * implies match any, the - against the target tells the filter to leave the values unchanged. So in the example above all tables and all columns will maintain the same name, but the schemas will be remapped from customer1 -> customer_merge, customer2 -> customer_merge etc., etc.
Testing It Out!
When I set this up in my lab environment, I kept my source tables very simple and just used 3 source schemas, but the results were perfect and just what was needed.
In the source, the table data was as follows:
mysql> select * from customer1.custdata;
+----+-----------------+
| id | msg |
+----+-----------------+
| 1 | Customer1 in C1 |
| 2 | Customer2 in C1 |
+----+-----------------+
2 rows in set (0.00 sec)mysql> select * from customer2.custdata;
+----+-----------------+
| id | msg |
+----+-----------------+
| 1 | Customer1 in C2 |
| 2 | Customer2 in C2 |
+----+-----------------+
1 row in set (0.00 sec)mysql> select * from customer3.custdata;
+----+-----------------+
| id | msg |
+----+-----------------+
| 1 | Customer1 in C3 |
| 2 | Customer2 in C3 |
+----+-----------------+
2 rows in set (0.01 sec)After this had been replicated, the end result was:
demo=# select * from customer_merge.custdata;
id | msg | src_db
----+-----------------+-----------
1 | Customer1 in C1 | customer1
1 | Customer1 in C2 | customer2
1 | Customer1 in C3 | customer3
2 | Customer2 in C1 | customer1
2 | Customer2 in C2 | customer2
2 | Customer2 in C3 | customer3
(6 rows)
As you can see, the data is nicely merged and the new src_db column becomes part of the Primary Key on the target table to maintain data integrity and avoid PK conflicts.
Summary
In summary, a very simple implementation of Tungsten Replicator, utilizing 3 very powerful filters, has provided the customer with a robust solution that no longer requires nightly/hourly CPU/Memory intensive data loading processes. Instead, the data is replicated, in real-time and is always available for the business reporting needs.
There are other elements required when configuring a redshift applier which I haven’t outlined in detail in this blog, however these are all explained in detail in our extensive online documentation.

Comments
Add new comment