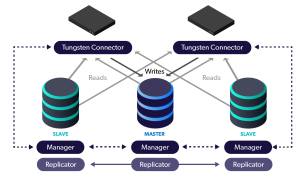
The Tungsten Replicator is an extraordinarily powerful and flexible tool capable of moving vast volumes of data from source databases to various targets like Vertica, Kafka, Redshift and so on.
In this blog post we will discuss the "cluster-slave" replicator topology which provides a way to extract data from a cluster even if a node should become unavailable. This means that data streams to your analytics platforms will continue to function even when there is a failure inside the source cluster.
The key to understanding how this works is to focus on the masterConnectUri and pipelineSource values within the trepctl status output:
masterConnectUri : thl://db1:2112/,thl://db2:2112/,thl://db3:2112/
pipelineSource : thl://db1:2112/
The above tells us two very import things:
masterConnectUriindicates that there are three possible sources for THL. THL is where each event is stored for transfer. Any running Replicator may serve THL to downstream slaves. The assumption is that no matter which node one pulls THL from in the source cluster, the downstream result is the same because the data is applied in order based on the sequence number.- The
pipelineSourceshows that this cluster-slave node has selected db1 as the source of the replication data. Pipeline sources are selected in the order listed. If the active source node were to go down, the Replicator will automatically attempt to connect to the next THL source node listed inmasterConnectUri.
Below is an example cluster-slave INI file designed for a slave MySQL node (db4) to act as a reporting/backup server which may be safely impacted by these activities which leaving the customer-facing cluster to continue serving at top speed.
Note that the line relay=db4 defines the hostname of the target slave node that the replicator software is installed upon.
[defaults]
user=tungsten
home-directory=/opt/continuent
datasource-user=tungsten
datasource-password=secret
start-and-report=true
[defaults.replicator]
home-directory=/opt/replicator
rmi-port=10002
[east]
connectors=db1,db2,db3
master=db1
members=db1,db2,db3
topology=clustered
[backups]
log-slave-updates=true
relay-source=east
relay=db4
topology=cluster-slave
root-command-prefix=true
thl-port=2114
For off-board deployments, simply add the hostname and port number to the service stanza, for example, install the software on relay host db4, and apply writes to host db7 running a cluster connector on port 3306:
[backups]
replicator-port=3306
replicator-host=db7
log-slave-updates=true
relay-source=east
relay=db4
topology=cluster-slave
root-command-prefix=true
thl-port=2114
This same concept also applies to non-MySQL targets. For example, here is an example INI snippet for an Elasticsearch reporting target on node db5:
...
[reporting]
topology=cluster-slave
relay-source=east
relay=db5
disable-security-controls=true
mysql-allow-intensive-checks=true
property=replicator.filter.convertstringfrommysql.definitionsFile=/opt/replicator/share/convertstringfrommysql.json
property=replicator.stage.remote-to-thl.filters=convertstringfrommysql
datasource-type=elasticsearch
replication-host=db5
replication-password=null
replication-port=9200
replication-user=root
svc-applier-filters=casetransform
property=replicator.filter.casetransform.to_upper_case=false
The Tungsten Replicator is extraordinarily flexible, with many possible targets, all while maintaining source cluster awareness for the highest availability.
We will continue to cover topics of interest in our next "Mastering Tungsten Replicator Series" post...stay tuned!
Click here for more online information about Continuent solutions...
Want to learn more or run a POC? Contact us.

Comments
Add new comment