The Tungsten Replicator is an extraordinarily powerful and flexible tool capable of moving vast volumes of data from source to target.
In this blog post we will discuss the internals of the Tungsten Replicator from the perspective of data flow processing.
A pipeline (or service) acts upon data.
Pipelines consist of a variable number of stages.
Every stage's workflow consists of three (3) actions, which are:
- Extract: the source for extraction could be the mysql server binary logs on a master, and the local THL on disk for a slave
- Filter: any configured filters are applied here
- Apply: the apply target can be THL on disk on a master, and the database server on a slave
Stages can be customized with filters, and filters are invoked on a per-stage basis.
By default, there are two pipeline services defined:
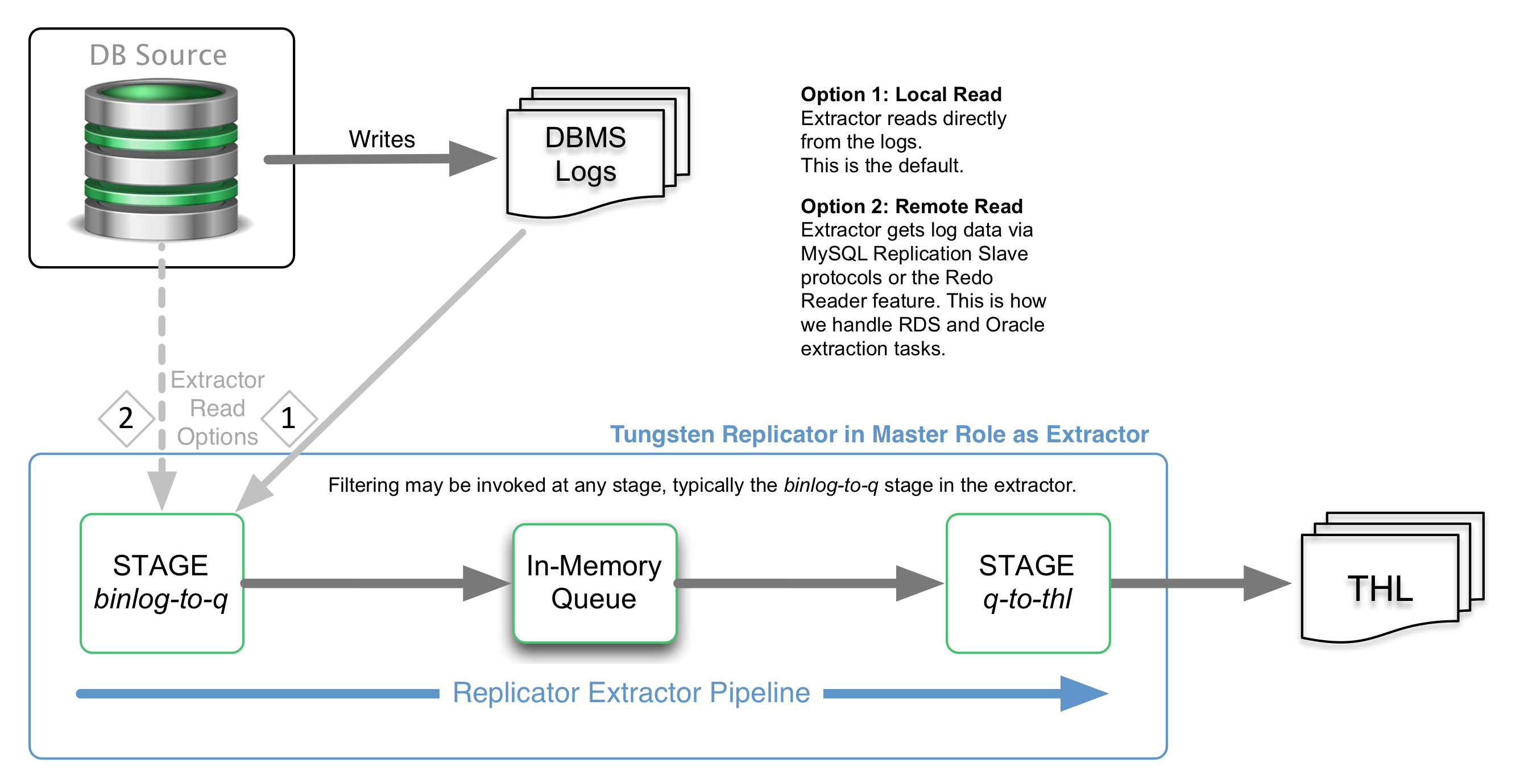
- The Master replication service (nicknamed "the extractor"), which contains two (2) stages:
- binlog-to-q: reads information from the MySQL binary log and stores the information within an in-memory queue.
- q-to-thl: in-memory queue is written out to the THL file on disk.
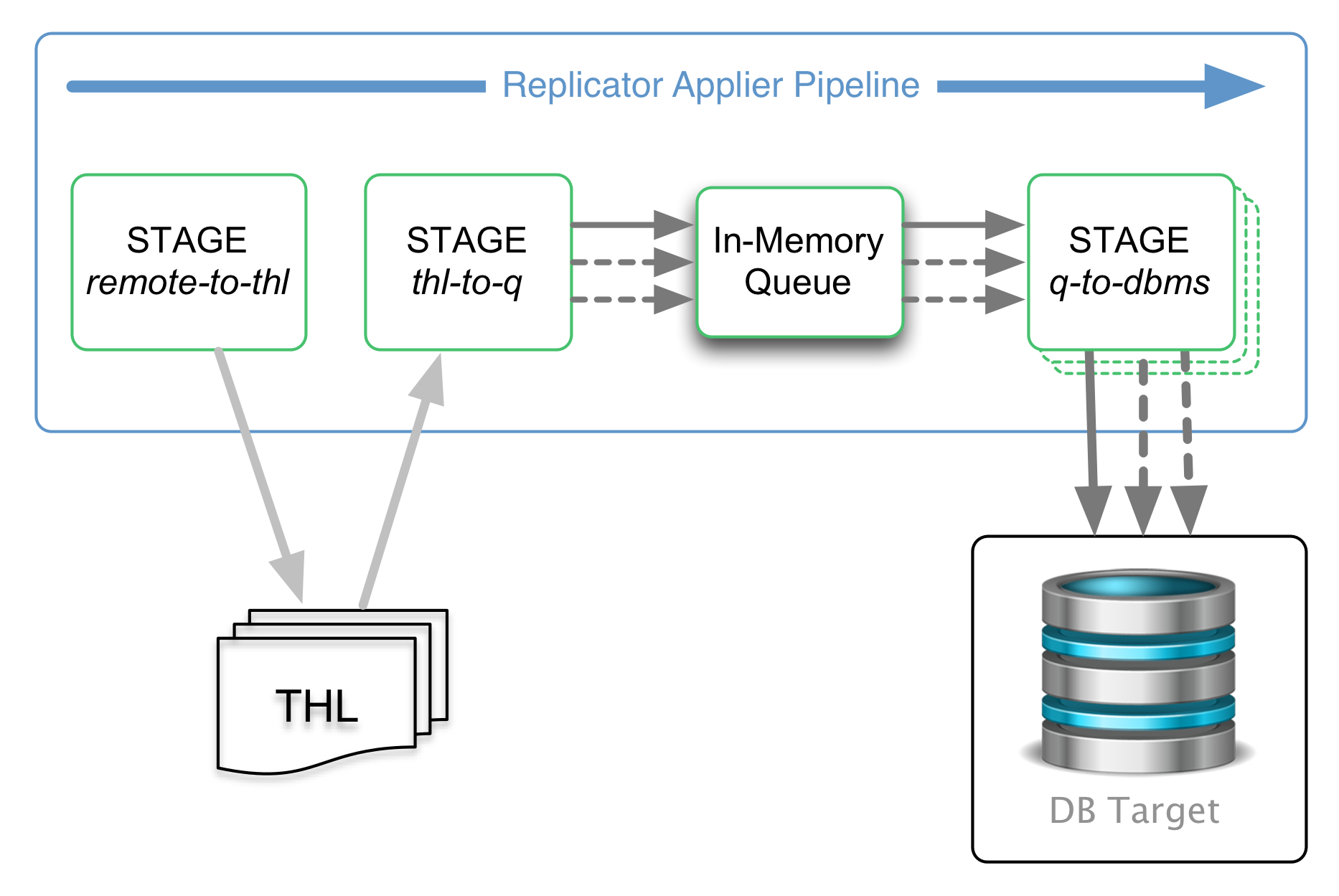
- The Slave replication service (nicknamed "the applier"), which contains three (3) stages:
- remote-to-thl: remote THL information is read from a master datasource and written to a local file on disk.
- thl-to-q: THL information is read from the file on disk and stored in an in-memory queue.
- q-to-dbms: data from the in-memory queue is written to the target database.
For more details about filtering, please visit the docs page at http://docs.continuent.com/tungsten-clustering-6.0/filters.html
We will continue to cover topics of interest in our next "Mastering Tungsten Replicator Series" post...stay tuned!
Click here for more online information about Continuent solutions...
Want to learn more or run a POC? Contact us.

Comments
Add new comment