Kubernetes has become the default platform for running stateless services at scale. When it comes to stateful workloads like MySQL, the picture is more complicated, especially across multiple geographic regions.
The appeal is obvious. Platform engineers want a single orchestration layer for everything: application services, caches, queues, and databases. Running MySQL inside Kubernetes means unified deployment pipelines, consistent infrastructure-as-code, and the ability to spin up entire environments declaratively. Running it across multiple regions extends those benefits to global availability, lower user-facing latency, and geographic compliance.
But MySQL is not a stateless HTTP service. It has durability requirements, replication topologies, write ordering constraints, and failover semantics that Kubernetes was not designed to manage. Stretching that across regions introduces network latency, split-brain risk, and consistency trade-offs that no amount of YAML will abstract away.
This post examines the architecture patterns that work for multi-region MySQL on Kubernetes, the Kubernetes-specific challenges that make each pattern harder than it looks, and what is required to operate these patterns safely in production environments.
Why Multi-Region MySQL on Kubernetes Is Hard
Before looking at patterns, it helps to understand the specific friction points that arise when MySQL, Kubernetes, and geographic distribution intersect. Each of these is manageable individually. In combination, they form the core complexity of the problem.
Kubernetes Assumes Replaceability
Kubernetes' scheduling model treats pods as disposable units that can be killed, rescheduled, and replaced at any time. That assumption works for stateless services. For MySQL, it collides with how databases preserve state.
A MySQL primary cannot simply be replaced - it must be demoted, and a specific replica must be promoted, in a coordinated sequence that respects replication position, transaction ordering, and the state of in-flight writes. If Kubernetes reschedules a primary pod to a different node (due to resource pressure, a node drain, or a preemption event), and nothing coordinates the resulting topology change, the outcome ranges from replication breakage to data loss.
This is why MySQL Operators exist: they encode the database-specific operational logic that StatefulSets alone do not cover. StatefulSets solve important problems - stable pod identities, stable storage via PVCs, and ordered startup and shutdown - but they have no concept of MySQL roles. They cannot distinguish a primary from a replica, coordinate a promotion, or manage replication topology. That is what Operators add. But in a multi-region context, the challenges go beyond what any current Operator solves on its own. Cross-region replication, lag-aware promotions, and failover decisions that account for geographic topology all sit outside the scope of a single Kubernetes cluster - and therefore outside the scope of Operators as they exist today. These concerns must be addressed by an additional coordination layer, whether that's custom tooling, an external cluster management system, or manual operational procedures.
Network Latency Is a First-Class Constraint
Within a single Kubernetes cluster, network round-trip times between pods are typically sub-millisecond. Between regions, they range from 20ms (nearby regions on the same continent) to 200ms+ (cross-ocean). This latency is governed by physics and cannot be eliminated by better infrastructure.
For MySQL, this has direct consequences. Synchronous replication protocols - which require every replica to acknowledge a transaction before the primary confirms the commit - add the full round-trip time to every write. A 100ms cross-region RTT means every single INSERT or UPDATE takes at least 100ms longer, regardless of how fast the underlying storage is. Under sustained write load, this becomes the dominant bottleneck. This is why multi-region MySQL architectures almost universally use asynchronous replication between regions. The primary commits locally and streams changes to remote replicas without waiting. Write performance is unaffected by distance.
The trade-off is a replication lag window during which the remote replicas are behind the primary. Under moderate, well-behaved workloads on a healthy network, this lag is often sub-second. Under sustained write pressure, large transactions, or resource contention, it can grow to seconds or even minutes. The size of that window directly determines the data loss exposure during a regional failover.
Kubernetes Networking Does Not Cross Regions Natively
A single Kubernetes cluster operates within one network boundary. Pods in one cluster cannot natively reach pods in another cluster in a different region. Multi-region MySQL therefore requires either stretching a single cluster across regions (possible with some managed Kubernetes offerings, but fraught with latency and availability issues) or running separate clusters per region and connecting them at the application or replication layer.
The separate-cluster model is overwhelmingly more common in production. As a result, cross-region concerns - replication, failover, and traffic routing - must be handled outside of Kubernetes' native abstractions. Kubernetes Services, Ingress controllers, and even most service meshes are scoped to a single cluster. Routing database traffic across regions requires additional infrastructure: global load balancers, DNS-based failover, or a database-aware proxy that understands the multi-region topology.
In practice, the network connectivity between regional Kubernetes clusters is established at the infrastructure layer, below Kubernetes itself. The most common approaches are VPC peering (connecting two cloud VPCs so that pods or nodes in one can reach the other via private IP), transit gateways (a hub-and-spoke model for connecting multiple VPCs across regions or accounts), VPN tunnels (encrypted site-to-site connections, often used for hybrid-cloud or multi-cloud deployments), or service mesh federation (tools like Istio's multi-cluster model, which can extend service discovery across clusters).
For MySQL replication specifically, the requirement is straightforward: the replica in region B must be able to reach the primary's MySQL port in region A over a reliable, low-latency link. How that link is provisioned - VPC peering, transit gateway, VPN, or direct peering - is a platform engineering decision that depends on your cloud provider, security posture, and existing network architecture. The architecture patterns that follow assume this cross-cluster connectivity is in place.
Persistent Storage Does Not Travel
PersistentVolumes in Kubernetes are bound to a specific availability zone and cloud provider. When a MySQL pod is rescheduled to a node in a different zone, the PV may not follow it. Across regions, storage definitely does not travel - the only way to have data in multiple regions is through replication.
This seems obvious, but it has implications that are easy to underestimate. You cannot fail over a MySQL primary to another region by simply moving a pod and its storage. You must promote a replica that already has the data, which means cross-region replication must be running continuously, monitored for lag, and ready for promotion at all times. The architecture must be designed to keep remote replicas as current as possible, because every second of replication lag translates directly into potential data loss during a regional failover.
Architecture Patterns
With those challenges in mind, there are a few architecture patterns commonly used for multi-region MySQL on Kubernetes. Each makes different trade-offs between consistency, latency, operational complexity, and cost.
Pattern 1: Single-Region Primary with Read Replicas
This is the simplest multi-region pattern and often the right starting point. One region runs the primary MySQL cluster (handling all writes), and remote regions run read replicas that serve local read traffic. Writes from all regions are routed to the primary.
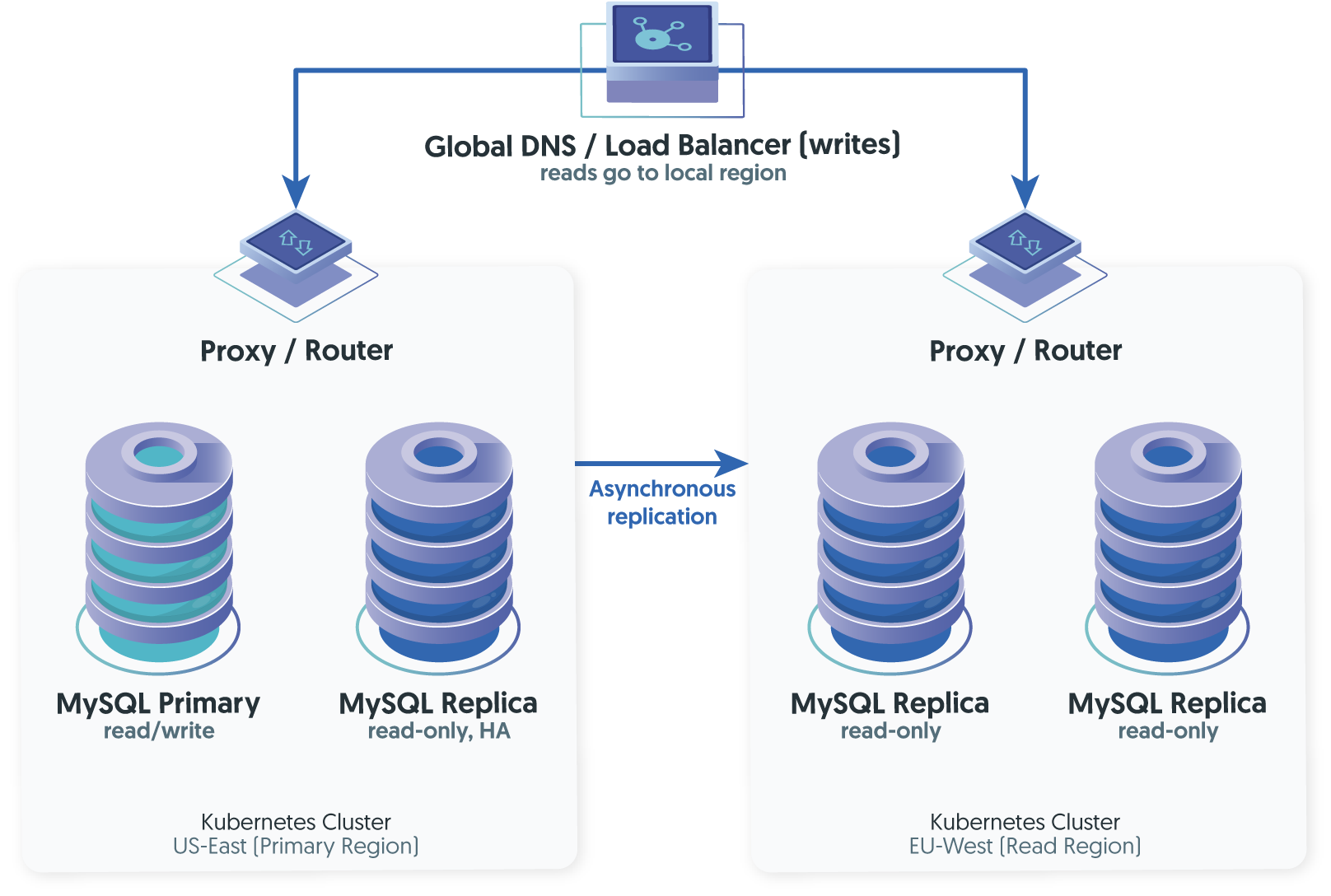
How It Works
The primary region handles all writes and serves local reads. Remote regions receive asynchronous replication and serve read-only traffic to nearby users. A global load balancer or DNS-based routing directs reads to the nearest region and writes to the primary.
What It Solves
Read latency for global users. The EU user reading product data gets sub-10ms response times from a local replica instead of 100ms+ from a cross-Atlantic query. The primary's write performance is unaffected by the remote replicas because replication is asynchronous.
What It Doesn't Solve
Write latency for remote users. Every write from Europe still travels to US-East. If the primary region goes down entirely, the read replicas cannot accept writes without a manual or semi-automated promotion - and that promotion carries a risk of data loss up to the replication lag at the moment of failure. Though, if the failed primary's binary logs are recoverable from disk, those transactions can still be applied to the promoted replica and the actual loss may be zero.
Kubernetes Specifics
Each region runs its own Kubernetes cluster with its own MySQL Operator managing the local topology. Cross-region replication is configured between clusters, typically using GTID-based asynchronous replication. The Operator in each region handles local failover (within that region's pods), but cross-region promotion requires either manual intervention or an external orchestration layer that understands the multi-cluster topology.
Best For
Applications that are read-heavy, can tolerate write latency from remote regions, and need geographic read scaling without the complexity of multi-region writes.
Pattern 2: Active-Passive with Regional Failover
This extends Pattern 1 by making the remote region a fully capable standby that can be promoted to primary if the primary region fails. The difference is operational: the secondary region runs a complete cluster (not just replicas), and the failover path is tested, documented, and ideally automated.
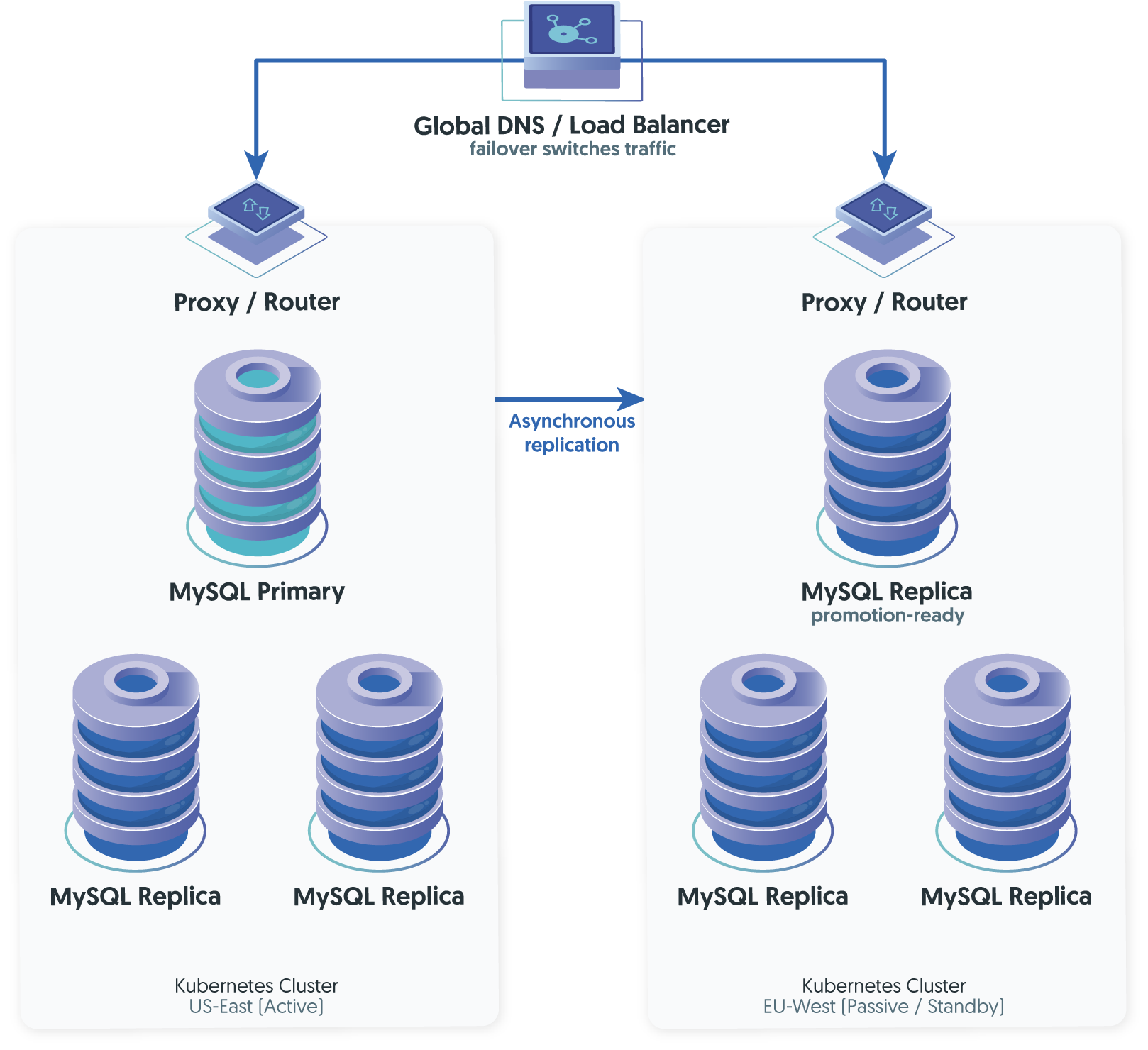
How It Works
Both regions run full MySQL clusters managed by their respective Operators. The active region accepts all writes. The passive region replicates asynchronously and serves reads. During a regional failure, the passive region is promoted: one of its replicas becomes the new primary, replication direction is reversed (when the original region recovers), and global DNS or a load balancer redirects write traffic.
The critical design question is how that failover is triggered. In a Kubernetes environment, you have several options with very different risk profiles.
- DNS-based failover uses health checks on the primary region's endpoints. When the health check fails, DNS records are updated to point to the secondary. This is simple to implement using Route 53, Cloud DNS, or similar services, but DNS TTLs introduce propagation delay - typically 30-60 seconds minimum, sometimes longer. Applications with cached DNS entries may continue sending traffic to the failed region after the cutover.
- Global load balancer failover (using something like AWS Global Accelerator, GCP's global LB, or Cloudflare) provides faster routing changes, but still requires the database layer to be ready for promotion. The load balancer can redirect traffic in seconds, but if the MySQL replica in the standby region hasn't finished applying the most recent transactions from the replication stream, you face a data consistency gap.
- Database-aware failover uses the cluster management layer itself - not the network layer - to make promotion decisions. This is where solutions like Tungsten Cluster differ from the DNS/LB approach. In VM and bare-metal deployments, Tungsten Manager uses a quorum of managers across regions to detect the failure, selects the most up-to-date replica for promotion, and coordinates the switchover through its Connector proxy so that application connections are redirected without relying on DNS propagation. This cross-region failover intelligence that Tungsten Cluster has been refined over more than a decade of production deployments. For Kubernetes environments, the Tungsten Operator manages the local cluster lifecycle within a single Kubernetes cluster, covering pod scheduling, PV management, failover between local replicas. The cross-region coordination layer (Manager quorum, Replicator, Connector routing) operates as the same proven infrastructure that handles multi-site deployments outside of Kubernetes. The Operator does not currently orchestrate across separate Kubernetes clusters; the cross-region layer sits above it.
Best For
Applications that need geographic disaster recovery, can tolerate a single write region during normal operation, and require reasonably fast (seconds to minutes) regional failover.
Pattern 3: Active-Active with Regional Writes
This is the most complex and most powerful pattern. Multiple regions accept writes simultaneously, each serving its local users with low-latency reads and writes. Data is replicated asynchronously between regions so that each region eventually has a complete copy.
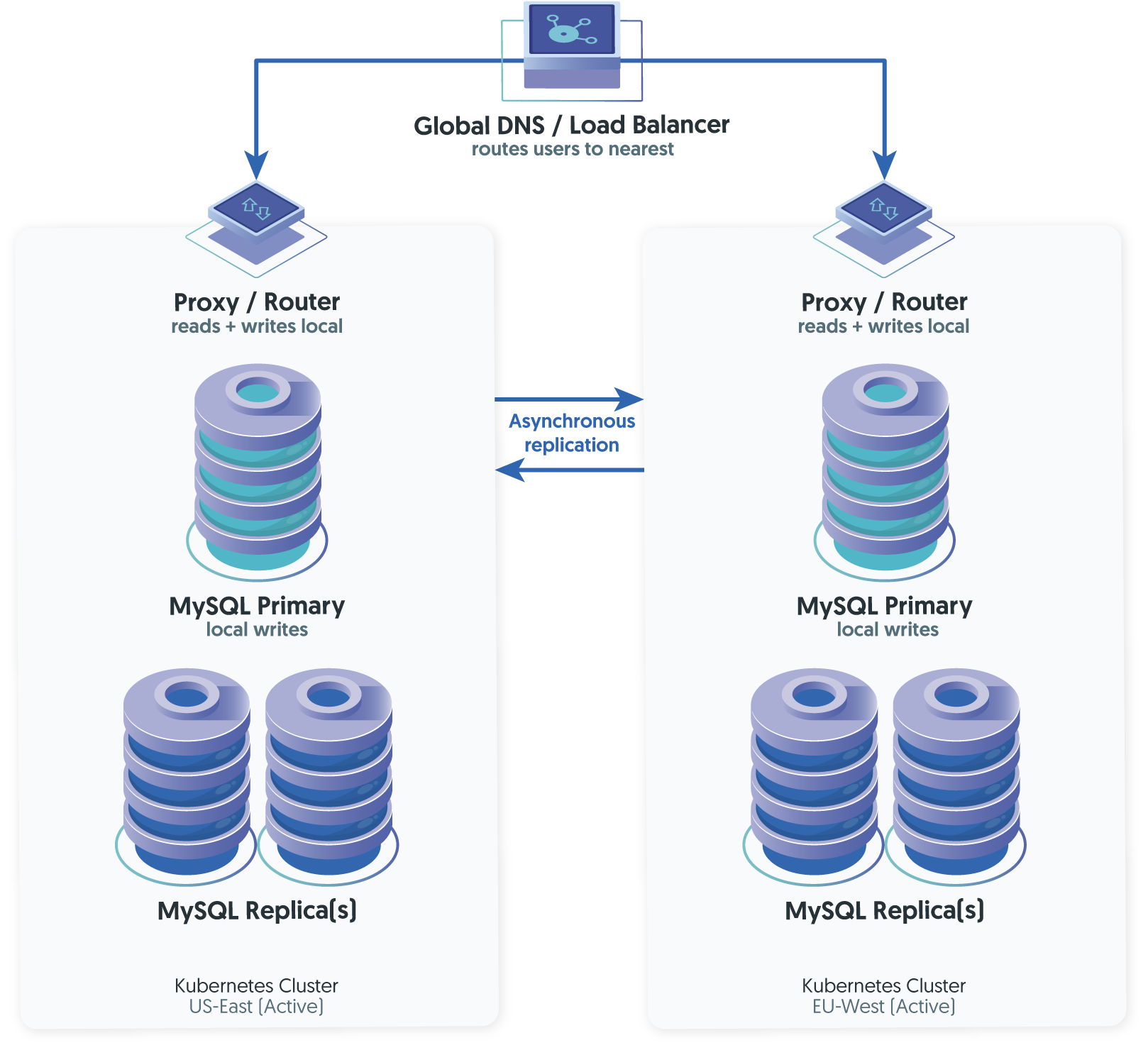
How It Works
Each region has its own writable primary. Changes made in one region are replicated to the other asynchronously. Users in each region read and write locally, experiencing low latency for all operations.
Why It's Hard
The fundamental challenge is with write conflicts. If two regions modify the same row at roughly the same time, the replication streams will carry contradictory changes. Without a conflict resolution mechanism, replication breaks or data silently diverges. We covered this in depth in our post on active-active MySQL replication - the short version is that active-active works well when data is naturally partitioned (each region mostly writes to its own slice) and requires careful engineering when it is not.
Kubernetes Specifics
In a Kubernetes context, active-active adds another layer of complexity: each region's Operator manages its own cluster independently, but the cross-region replication and conflict handling must be coordinated across clusters. Most MySQL Operators are designed for single-cluster management and have no awareness of a remote cluster's state.
How It's Implemented
Tungsten Cluster supports active-active through its Composite Active/Active and Dynamic Active/Active topologies, where each region has its own writable primary and Tungsten Replicator handles bidirectional asynchronous replication between them. The Tungsten Connector at each site routes local reads and writes to the correct primary, and handles automatic redirection during failover. For Kubernetes deployments, the Tungsten Operator manages the local cluster lifecycle within each region, while the broader Tungsten architecture handles the cross-region coordination.
InnoDB Cluster's Group Replication can be used in multi-primary mode, but it requires all nodes to be within a single low-latency cluster. Stretching it across regions produces severe write performance degradation due to the synchronous certification protocol. InnoDB ClusterSet uses asynchronous replication between sites, but only allows one writable primary cluster at a time, making it effectively active-passive at the site level.
Best For
Applications with naturally partitioned data (multi-tenant SaaS with regional tenants, for example), teams with mature operational practices, and workloads where write latency from remote regions is unacceptable.
The Proxy Layer: A Cross-Cutting Concern
An intelligent proxy is not a separate architecture pattern. Instead, it is a layer that can be applied on top of any of the three patterns above. In each case, a database-aware proxy deployed in every region makes the multi-region topology transparent to the application. The application connects to a local proxy endpoint and issues standard MySQL queries. The proxy routes writes to whichever region currently holds the primary and serves reads from local replicas. The application does not need separate connection strings for reads and writes, does not need to know which region is active, and does not need to handle reconnection logic during failover.
This is the architectural approach behind Tungsten Connector, and to varying degrees, behind ProxySQL and MySQL Router. In a Kubernetes deployment, the proxy runs as a dedicated pod within each region's cluster, exposing a standard Service endpoint that application pods connect to. For platform engineers, this means that the database topology becomes an infrastructure concern. Developers write standard MySQL queries, and the routing, failover, and read/write splitting happen below the application layer.
Whether you use Pattern 1, 2, or 3, adding an intelligent proxy layer is almost always worth the operational investment. Without it, every application team that consumes the database must implement its own routing and failover logic. As a result, the same complexity is duplicated across every service instead of being solved once at the infrastructure level.
Consistency Models and Their Implications
Regardless of which pattern you choose, you must decide what consistency guarantees your application requires - and accept the trade-offs that come with each.
- Strong consistency (every read returns the most recent write) requires either synchronous replication or routing all reads to the primary. In a multi-region setup, this means either accepting synchronous replication's latency penalty or accepting that all reads go to one region. Few multi-region architectures use strong consistency for all operations.
- Eventual consistency (replicas catch up over time, and reads may return slightly stale data) is the practical default for multi-region MySQL. The staleness window equals the replication lag - which can range from sub-second under moderate workloads to seconds or minutes under sustained writes, large transactions, or resource contention. Most applications tolerate this for read traffic. Product catalog pages, user profiles, dashboards, and reports can all be served from eventually consistent replicas without users noticing.
- Session consistency (a user always sees their own most recent writes) is a middle ground that works well in practice. After a user performs a write, subsequent reads from that user's session are routed to the primary (or to a replica known to have applied that transaction). This requires session-aware routing logic in the proxy layer - something that a generic load balancer cannot provide, but that a database-aware proxy can.
The right model often varies by operation within the same application. A checkout flow may require strong consistency for the payment transaction, but can tolerate eventual consistency for the order confirmation page. Designing the routing rules to match these requirements per-operation is where an intelligent proxy adds the most value.
DNS, Load Balancing, and Traffic Routing
How application traffic reaches the correct MySQL endpoint across regions is a problem that sits at the intersection of networking, DNS, and database awareness. Each approach has distinct trade-offs.
- Cloud-native global load balancers (AWS Global Accelerator, GCP External Application LB, Azure Front Door) provide fast, health-check-based routing at the network layer. They can direct traffic to the nearest healthy region in seconds. The limitation is that they don't understand MySQL semantics - they see TCP connections and HTTP health checks, not replication state or primary/replica roles. A health check may pass on a MySQL replica that is online, but 30 seconds behind the primary, leading the load balancer to route traffic to a stale node.
- DNS-based failover (Route 53, Cloud DNS, external DNS) is simpler, but slower. DNS TTLs create a floor on failover speed - typically 30-60 seconds minimum, sometimes much longer due to client-side caching. For disaster recovery scenarios where minutes of downtime are acceptable, this works. For HA requirements measured in seconds, DNS is too slow.
- Database-aware proxy routing pushes the routing decision into a layer that understands the MySQL topology. A proxy that knows which node is the primary, which replicas are current, and which region is active can make correct routing decisions instantly - without waiting for DNS propagation or relying on generic health checks. This is the model used by Tungsten Connector, ProxySQL (with appropriate configuration), and MySQL Router (with limitations). In a Kubernetes context, the proxy runs as a sidecar or a dedicated pod within each region's cluster, exposing a standard Service endpoint to application pods.
For most multi-region architectures, the practical answer is a combination: a global load balancer or DNS for directing users to the nearest region's application layer, and a database-aware proxy within each region for routing queries to the correct MySQL node. The two layers solve different problems and should not be conflated.
The Operator Question
A MySQL Operator manages the lifecycle of MySQL within a Kubernetes cluster: deployment, scaling, failover, backup, and upgrades. For multi-region architectures, the question is whether the Operator's scope extends beyond a single cluster.
Most MySQL Operators - including Oracle's MySQL Operator, Percona's PXC Operator, and KubeDB - are designed to manage a single Kubernetes cluster. They handle local HA (promoting a replica if the primary pod fails within the cluster), but do not coordinate cross-region replication or cross-region failover. This means that in real multi-region deployments, the most critical failure scenarios sit outside the scope of the Operator itself. For a detailed comparison, see our earlier analysis.
This means that in Patterns 1-3 above, if you use a single-cluster Operator, the cross-region coordination layer must be built or sourced separately. Cross-region replication setup, lag monitoring, failover orchestration, and traffic re-routing all fall to the platform team, who must address them either through custom tooling or by adopting a solution that provides these capabilities natively.
Tungsten Operator takes a different approach because it deploys the Tungsten Cluster stack (Manager, Replicator, Connector) inside Kubernetes rather than just MySQL itself. Within a single Kubernetes cluster, this gives the Operator access to Tungsten's proven failover logic, intelligent proxy routing, and replication management. For multi-region deployments, the cross-region coordination (Manager quorum across sites, cross-site replication, site-level failover) uses the same Tungsten components that handle these concerns in VM and bare-metal environments. The Operator manages the Kubernetes-native lifecycle per region; the cross-region layer operates above it, providing a consistent and proven coordination model across regions that would otherwise require custom tooling and operational overhead.
This is an important architectural distinction: no other MySQL Operator on the market today fully orchestrates multi-region deployments across separate Kubernetes clusters as a single declarative resource.
Practical Recommendations
Several practices consistently separate successful multi-region MySQL deployments on Kubernetes from fragile ones.
-
Start with Pattern 1 and earn your way to Pattern 3
Most teams that jump directly to active-active without mastering single-primary replication across regions end up fighting conflicts, debugging inconsistencies, and eventually retreating. Begin with a single write region and read replicas. Add regional failover capability (Pattern 2) when your disaster recovery requirements demand it. Move to active-active (Pattern 3) only when your data model naturally partitions by region and your team has the operational maturity to manage bidirectional replication. -
Treat replication lag as a metric, not an afterthought
In a multi-region deployment, replication lag determines your data loss exposure during failover, the staleness of your read replicas, and the consistency guarantees you can offer to applications. Monitor it continuously, alert on deviations from baseline, and understand what causes it to spike in your environment. If you haven't already, our series on MySQL replication lag covers the mechanics in depth. -
Test regional failover under production conditions
Not in staging. Not with synthetic traffic. With real users and real load. Controlled switchovers - where you intentionally promote the secondary region while the primary is still healthy - are the safest way to validate your failover path end-to-end. If you discover problems during a controlled test, you can switch back. If you discover them during an actual outage, you cannot. -
Separate the routing layer from the application layer
Applications should connect to a local MySQL endpoint and issue standard queries. They should not contain logic for detecting regional failures, selecting replica endpoints, or distinguishing reads from writes. All of that belongs in the proxy layer. This separation makes the database topology an infrastructure concern that can be changed without redeploying application code. -
Use affinity and topology constraints aggressively
In Kubernetes, MySQL pods should be pinned to specific zones, nodes, or topology domains using pod anti-affinity, topology spread constraints, and node selectors. MySQL is sensitive to noisy-neighbor effects. CPU or disk contention from co-located workloads can starve the InnoDB buffer pool, slow redo log writes, and create replication lag. Dedicated node pools for database workloads are common in production multi-region deployments. -
Plan for the control plane, not just the data plane
The Kubernetes control plane, the MySQL Operator, the replication management layer, and the monitoring system all need to be available for the multi-region system to function correctly. A regional outage that takes down both the data plane and the control plane in one region should not prevent the other region from operating independently. This means running independent Operators per region, ensuring that whatever cross-region coordination layer you use (whether Tungsten Manager, custom tooling, or manual procedures) can function independently of any single region's Kubernetes control plane, and ensuring monitoring is not colocated exclusively with the primary database region.
Summary
Multi-region MySQL on Kubernetes is not a single problem with a single solution. It is a set of layered challenges - Kubernetes' stateless assumptions, cross-region network latency, storage locality, replication consistency, and traffic routing - each of which narrows the design space and requires explicit trade-off decisions.
The three patterns described here - read replicas, active-passive failover, active-active writes - represent the most common topologies, and most production deployments are either using one of them or evolving between them. An intelligent proxy layer, applied on top of whichever pattern you choose, separates the routing complexity from the application and is worth the investment in almost every case.
The choice of Operator and tooling matters, but it matters less than the architectural decisions that precede it. Decide on your consistency model first. Decide whether you need multi-region writes or whether single-region writes with geographic read scaling is sufficient. Decide what your failover targets are and test whether your chosen approach actually meets them. Then select tools that implement those decisions well, whether that's a combination of open-source components or an integrated solution like Tungsten Cluster.
The organizations that succeed at multi-region MySQL on Kubernetes are the ones that treat it as an architecture problem, not a deployment problem. The Kubernetes manifests are the easy part. The hard part is the design that makes them work across oceans.

Comments
Add new comment