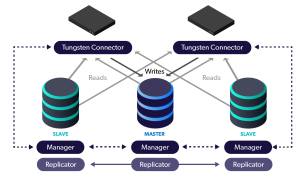
In this blog post, we discuss failover concepts and administration.
Failover Triggers
So when is a failover triggered, anyway? Believe it or not, there is only ONE single condition that causes a failover in a Tungsten Cluster - loss of the TCP socket connection to the MySQL database server.
By default, no other trigger causes a failover by design.
This has occasionally caused confusion when other factors impact MySQL server, yet the cluster does not fail over, for example when the server gets very slow.
What if the cluster does not failover and MySQL is misbehaving?
A recent support case illustrated this situation. The database server appeared to be hung, yet the socket was alive. The master was effectively in an error state, and the DBA needed to force a failover.
A cluster failover may be triggered manually via the command line or through the Tungsten Dashboard.
First, identify the hostname of the bad master:
shell> cctrl
cctrl> ls
Next, inform the cluster that the bad master is failed:
cctrl> datasource {BadMasterHostNameHere} fail
cctrl> ls
Lastly, if the cluster has not automatically triggered a failover at this point, tell it to do so manually:
cctrl> failover
cctrl> ls
The Nitty Gritty
A cluster does monitor a large variety of items as reflected in the /opt/continuent/tungsten/cluster-home/conf/statemap.properties.defaults file.
***IMPORTANT: Please do NOT hand-edit this file unless instructed by Continuent support. Any changes to this file WILL alter the cluster behavior and Continuent cannot predict cluster behavior if this file is modified by hand.
The mappings in this file determine the way that the Tungsten manager and rules interpret the return status from utilities that probe the state of a database server. This mapping, in turn, can directly drive whether or not a particular probe return status can trigger, for example, a failover or just cause the database server state to be updated with a different status.
For example, see the extract below. The only section that is configured to trigger a failover is socket_io_error because socket_io_error.action=fail:
...
#
# Status values that indicate the db server is definitively stopped
#
socket_io_error.state = stopped
socket_io_error.threshold = 0
socket_io_error.action = fail
#
# Status values that indicate some sort of timeout condition
#
socket_connect_timeout.state = timeout
#socket_connect_timeout.threshold = 5
#socket_connect_timeout.action = fail
socket_connect_timeout.threshold = -1
socket_connect_timeout.action = none
login_response_timeout.state = timeout
#login_response_timeout.threshold = 5
#login_response_timeout.action = fail
login_response_timeout.threshold = -1
login_response_timeout.action = none
...
If the login_response_timeout section were changed to look like the following, then a failover would also be triggered if the manager is no longer able to get a login response from the MySQL database server.
login_response_timeout.threshold = 5
login_response_timeout.action = fail
#login_response_timeout.threshold = -1
#login_response_timeout.action = none
The change needs to be done on all nodes, and a manager restart is required on all nodes to make the changes take effect.
In future articles, we will continue to cover more advanced subjects of interest!
Questions? Contact Continuent

Comments
Add new comment