First off: Happy 15th birthday, Hadoop!
It wasn’t an April Fool’s joke then, and it isn’t today either: Hadoop’s initial release was on the 1st of April 2006 :-)
As most of you will know, Apaches Hadoop is a powerful and popular tool, which has been driving much of the Big Data movement over the years. It is generally understood to be a system that provides a (distributed) file system, which in turn stores data to be used by applications without knowing about the structure of the data. In other words, it’s a file system that stores a spreadsheet for example as a set of elements, but without it knowing about its cells, formulas, etc.
The foundational technology of Hadoop was originally invented by Google way back when, who needed to index all the textural and structural information they were collecting in a useful way, and from there be able to offer useful results to their users. They couldn’t find any technology that did this at the time, and so they created their own. This explains well where the need for something like Hadoop arose from.
Since this is a MySQL to Hadoop replication blog - a nice anecdotal similarity between MySQL and Hadoop: Doug Cutting, one of Hadoop’s co-founders, named Hadoop after his son's toy elephant. Open source software creators appear to like naming their creations after their children or in relation to them.
Hadoop is designed to run on a large number of machines that hold massive amounts of data and that don’t share any memory or disks.
Hadoop & Big Data
Big data and the use of big data solutions for the processing and analysis of customers and logging data has continuously been increasing at a substantial rate. But whereas previously the analytical processing of data was handled in an offline and often separate part of the data processing process, Hadoop is now seen as an active part of the data flow. Rather than offline analytics, Hadoop is playing an active role in the processing and provisioning of data directly to the customer.
This presents a number of issues within the data exchange and migration process when using existing toolsets. They rely on a highly manual, periodic and intermittent transfer of information often closely tied to the previously non-interactive nature of the data transfer process such as a periodic ETL workflow.
Because of this, data needs to be loaded into Hadoop not in intermittent batches, but as an active database that sits alongside existing relational, NoSQL, and other databases. This allows data to be actively and constantly exchanged between the different database environments, ensuring consistency of the shared information.
Why Hadoop
Some of the main reasons Hadoop is being used include:
- Scales to thousands of nodes (TB of structured and unstructured data)
- Combines data from multiple sources, schemaless
- Users can run queries against all of the data
- Runs on commodity servers (handle storage and processing)
- Data replicated, self-healing
- Initially just batch (Map/Reduce) processing
- Extending with interactive querying, via Apache Drill, Cloudera
Impala, Stinger etc.
- Extending with interactive querying, via Apache Drill, Cloudera
The Hadoop platform was designed for organisations or situations that involve a lot of data, such as a mixture of complex and structured data, and where that data doesn’t necessarily fit into tables. It’s designed for running extensive analytics as is the case with clustering and targeting.
Why Replicate From MySQL to Hadoop
There are any number of scenarios where replication from MySQL to Hadoop may be needed, including some of the following:
- Users who have large MySQL production tables that they want to analyze.
- Organisations that have a stack which uses Hadoop, Hive and Impala for analysing big data and who need to import data from a MySQL table.
- Large MySQL databases with heavy load where the user would like to replicate quickly to Hbase in order to do analytical work, but without any schema changes for example.
- Users looking for a way to transfer data from MySQL to Hadoop online, so that real time analytics can be achieved.
Tungsten Replicator (AMI) for Hadoop
Tungsten Replicator provides an alternative to other solutions out there in the market based on an existing, well- tested replication technology already used for both homogeneous and heterogeneous replication between MySQL (source or target) and a range of other database targets.
It provides high-performance and improved replication functionality over the native MySQL replication solution and into a range of targets / databases, such as Hadoop of course… as well as MySQL (all versions), Oracle, Vertica, AWS RedShift, ClickHouse, Kafka, MongoDB & PostgreSQL.
It is the most advanced heterogeneous replication solution for MySQL, MariaDB & Percona Server, including Amazon RDS MySQL and Amazon Aurora. It’s available as an AMI and can be accessed via AWS.
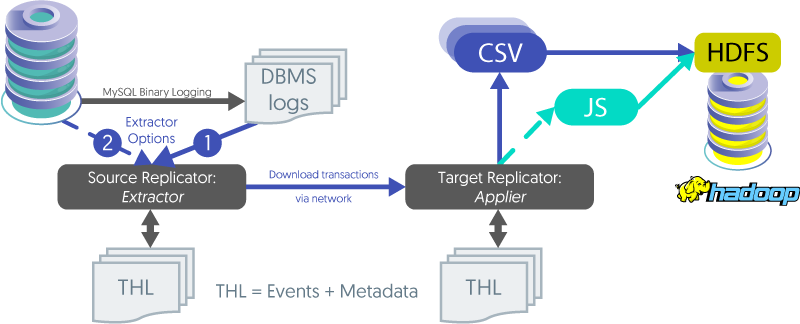
How Replication to Hadoop Works
Option 1: Local Install
Extractor reads directly from the logs, even when the DBMS service is down. This is the default.
Option 2: Remote Install
Extractor gets log data via MySQL Replication protocols (which requires the DBMS service to be online) This is how we handle Amazon Aurora extraction tasks.
Provisioning Options for Hadoop
| Manual via CSV | Sqoop | Tungsten Replicator | |
|---|---|---|---|
| Process | Manual/Scripted | Manual/Scripted | Fully Automated |
| Incremental Loading | Possible with DDL changes | Requires DDL changes | Fully Supported |
| Latency | Full-load | Intermittent | Real-time |
| Extraction Requirements | Full table scan | Full and partial table scans | Low-impact CDC/binlogscan |
Replication Support for Hadoop
- Extract from MySQL
- Hadoop Support
- Cloudera (Certified), HortonWorks, MapR, Pivotal, Amazon EMR, IBM (Certified), Apache
- Provision using Sqoop or parallel extraction
- Schema generation for Hive
- Tools for generating materialized views
- Parallel CSV file loading
- Partition loaded data by commit time
- Schema Change Notification
How the Tungsten Replicator (AMI) Can Be Used
Tungsten Replicator (AMI) supports a number of different topologies, and these can be exploited when combined with the Hadoop applier to enable a range of different data replication structures.
A standard replication service could replicate data from multiple MySQL servers into a single Hadoop cluster, using Hadoop to provide the consolidation of information. This can be useful when you have multiple MySQL servers providing a shared data architecture, but want to perform analytics on the full body of data across all servers. For example, a fan-in topology with multiple sources applied to one Hadoop target.
Alternatively, a ‘fan-in aggregation’ topology enables data to be combined within a MySQL server before replication into Hadoop.
Different replicators and heterogeneous targets can also be combined, reading from the same Tungsten Replicator extractor, and applying to multiple different hetero-geneous targets. For example, Tungsten Replicator could be configured to read information from the extractor and replicate some of this information into a MongoDB server for use by the application servers for document-based access to the content.
Simultaneously, the data could also be written into a Hadoop cluster for the purposes of analytics to analyze the entire database or change information.
How to Get Started With the Tungsten Replicator AMI
Getting started with the 14-Day free trial
Users can try one instance of each type of the AMI for free for 14 days to get them started (AWS infrastructure charges still apply).

Please note that free trials will automatically convert to a paid hourly subscription upon expiration and the following then applies in the case of Hadoop targets.
Replicate from AWS Aurora, AWS RDS MySQL, MySQL, MariaDB & Percona Server to Hadoop from as little as $2.07/hour
With Tungsten Replicator (AMI) on AWS, users can replicate GB's of data from as little as $40c/hour:
- Go to the AWS Marketplace, and search for Tungsten, or click here.
- Choose and Subscribe to the Tungsten Replicator for MySQL Source Extraction.
- Choose and Subscribe to the target Tungsten Replicator AMI of your choice.
- Pay by the hour.
- When launched, the host will have all the prerequisites in place and a simple "wizard" runs on first launch and asks the user questions about the source and/or target and then configures it all for them.

Watch the Getting Started Walkthrough
Our colleague Chris Parker recorded this handy walk-through on how to get started with the Tungsten Replicator AMI if you need some tips & tricks.

Extraction and Appliers
Below you’ll find the full listing of extractors and appliers that are available with Tungsten Replicator.
Replication Extraction from Operational Databases
- MySQL (all versions, on-premises and in the cloud)
- MariaDB (all versions, on-premises and in the cloud)
- Percona Server (all versions, on-premises and in the cloud)
- AWS Aurora
- AWS RDS MySQL
- Azure MySQL
- Google Cloud SQL
Available Replication Target Databases
Do give Tungsten Replicator AMI a try and let us know how you get on or if you have any questions by commenting below!
Related Blogs
Check out our related blogs if you’re (also) working with these databases / platforms:
- Vertica: Real-Time MySQL Analytics — How to Replicate Data in Real-Time from MySQL, MariaDB or Percona Server to Vertica
- PostgreSQL: How Replication to PostgreSQL Works: Replicating Data in Real-Time from MySQL, MariaDB or Percona Server to PostgreSQL
- Kafka: How Replication Between MySQL & Kafka Works: Replicating Data in Real-Time from MySQL, MariaDB or Percona Server to Kafka
- MongoDB: How to Replicate from MySQL to MongoDB (incl. MongoDB Atlas)

Comments
Add new comment