Introduction
When doing systems and database administration, there are often multiple ways to get the job done.
While each of those ways may work, there is often one way that is called the “best practice”, meaning that it is the agreed-upon best workflow to accomplish that specific goal.
With Tungsten Clustering software, the same holds true.
In this blog post, we cover the correct method for doing Tungsten software upgrades.
Deployment Methods — A Quick Review
There are two ways to install the Tungsten software - the Staging and INI deployment methods. The end result is the same, but the use-case differs.
| The Staging deployment method was the first way to install, and it relies upon password-less SSH between the staging host where the software installer package is downloaded, extracted and executed. The host where the installer runs does not need to be a cluster node, but it could be. The installation happens on all nodes at the same time in parallel. The same holds true for upgrades - they happen on all nodes at once. |
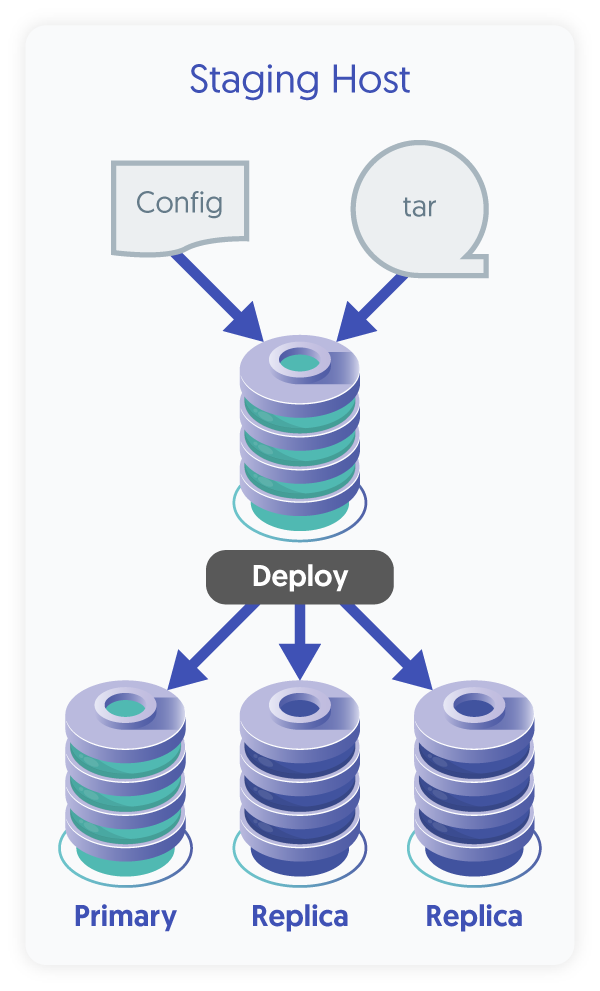 |
| The INI deployment method came later in response to the proliferation of DevOps tools like Ansible, Puppet and Chef. When using the INI method, the installer package is downloaded, extracted and executed on every associated node (databases, connectors, witnesses, etc.). No SSH is required, and so this installation type can be considered more secure. Since INI installs happen individually per host, they do not need to run all at the same time, but could be. INI upgrades also may be done one at a time or all at once. |
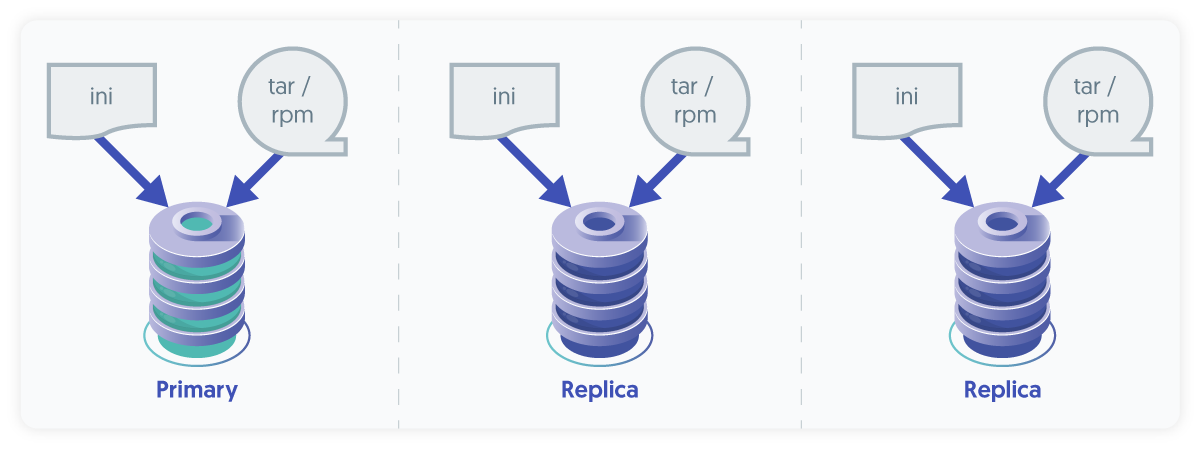 |
For more details, please visit “Comparing Staging and INI tpm Methods” in our Docs.
Tungsten Upgrades: The Way
The best practice for Tungsten software is to upgrade all nodes at once without a switch.
The Staging deployment method automatically does an all-at-once upgrade - this is the basic design of the Staging method.
“Just because you can do a thing, does not mean you should do that thing.”
There are many reasons why doing an upgrade on all nodes at once without a switch is the correct choice:
- Prevents mixed versions of the Tungsten software on different nodes
- Allows the Replicators to come back online as quickly as possible
- Takes the least amount of time, and so has the least disruption and the least risk
- Prevents corner-case issues when running mixed versions
- Allows the cluster to return to Automatic policy mode; otherwise, the cluster would need to stay in Maintenance mode for safety
Here is the sequence of events for a proper Tungsten upgrade on a 3-node cluster with the INI deployment method:
- Login to the Customer Downloads Portal and get the latest version of the software
- Copy the file (i.e. tungsten-clustering-7.0.2-161.tar.gz) to each host that runs a Tungsten component
- Set the cluster to policy Maintenance
- On every host:
- Extract the tarball under
/opt/continuent/software/- i.e. create
/opt/continuent/software/tungsten-clustering-7.0.2-161
- i.e. create
- cd to the newly extracted directory
- run the installer tool
- Extract the tarball under
For example, here are the steps in order:
-
On ONE database node:
shell> cctrl cctrl> set policy maintenance cctrl> exit -
On EVERY Tungsten host at the same time:
shell> cd /opt/continuent/software shell> tar xvzf tungsten-clustering-7.0.2-161.tar.gz shell> cd tungsten-clustering-7.0.2-161 -
To perform the upgrade and restart the Connectors gracefully at the same time:
shell> tools/tpm update --replace-release -i -
To perform the upgrade and delay the restart of the Connectors to a later time:
shell> tools/tpm update --replace-release --no-connectors -i -
When it is time for the Connector to be promoted to the new version, perhaps after taking it out of the load balancer:
shell> tpm promote-connector -
When all nodes are done, on ONE database node:
shell> cctrl cctrl> set policy automatic cctrl> exit
Tungsten Upgrades: The Nitty Gritty
WHY is it ok to upgrade and restart everything all at once?
Let’s look at each component to examine what happens during the upgrade, starting with the Manager layer.
Once the cluster is in Maintenance mode, the Managers cease to make changes to the cluster, and therefore Connectors will not reroute traffic either and simply continue to send queries as before.
Since Manager control of the cluster is passive in Maintenance mode, it is safe to stop and restart all Managers - there will be zero impact to the cluster operations.
The Replicators function independently of client MySQL requests (which come through the Connectors and go to the MySQL database server), so even if the Replicators are stopped and restarted, there should be only a small window of delay while the replicas catch up with the Primary once upgraded. If the Connectors are reading from the Replicas, they may briefly get stale data if not using SmartScale.
Finally, when the Connectors are upgraded, they must be restarted, so the new version can take over. As discussed in this previous blog post, the Tungsten Cluster software upgrade process will do two key things to help keep traffic flowing during the Connector upgrade promote step:
- Execute `
connector graceful-stop 30` to gracefully drain existing connections and prevent new connections. - Using the new software version, initiate the start/retry feature, which launches a new connector process while another one is still bound to the server socket. The new Connector process will wait for the socket to become available by retrying binding every 200ms by default (which is tunable), drastically reducing the window for application connection failures.
Wrap-Up
In this post we explored the correct procedure for upgrading a Tungsten cluster when using the INI deployment method by upgrading all nodes at once without a switch.
Smooth sailing!

Comments
Add new comment