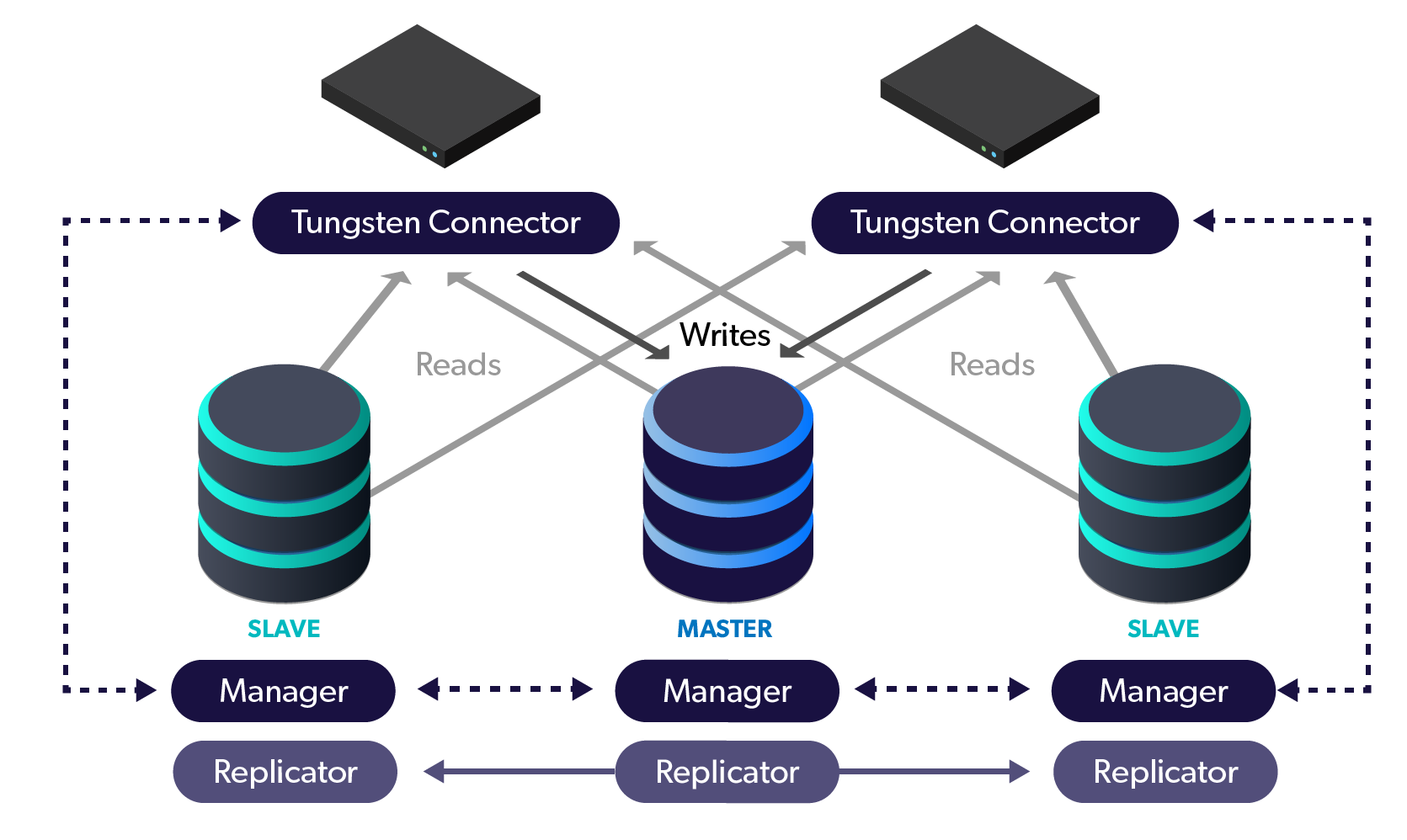
When deploying Tungsten Clustering for MySQL / MariaDB / Percona Server, we always recommend an odd number of Manager nodes in each cluster. Let's take a look at how having an odd number of Managers helps keep a Tungsten Cluster functioning and avoids data corruption scenarios (i.e. "split brain").
The Question
Why does a cluster need an odd number of nodes to function properly?
The Short Answer
For a cluster to select the correct master node during a network outage, there is a vote to see which nodes are reachable. The majority of nodes will shut out the minority and the Managers will signal the Connectors as to the proper master node. If a Connector is unable to reach a Manager, it will pause all incoming connections after a timeout.
An Excellent Post About Connector Behavior
In order to be able to avoid split brain, a cluster needs an odd number of members such that if there is a network partition, there's always a chance that a majority of the members are in one of the network partitions. If there is not a majority, it's not possible to establish a quorum and the partition with the master, and no majority, will end up with a shunned master until such time a quorum is established.
To operate with an even number of database nodes, an active witness node is required, since the dynamics of establishing a quorum are more likely to succeed with an active witness than with a passive witness. The passive witness feature will be deprecated in Tungsten Clustering v6.1.
Additionally, you may tune the behavior and timeouts of the manager.
The Nitty Gritty
Each manager in a cluster is constantly performing checks on its host and communicating with other managers in the cluster. There are close to 100 rules for the manager to check! During a communications failure, a process of “voting” takes place within all of the active managers. The results of the vote will determine if a failover happens within a cluster. Having an odd number of nodes or “votes” ensures that there is never a tie during a vote, and a tie is exactly what we want to avoid.
What happens if there would be a tie? With no clear winner in the decision to failover, the cluster would be partitioned, having active nodes that cannot communicate with each other and advertise themselves as online. This will lead to corruption, as data is updated in each partition but never communicated back to the other partitioned cluster. Commonly known as “split-brain,” we avoid this scenario at all costs.
As an example, let’s look at the cluster in the diagram below. We have a four node cluster configured in two separate networks, and let’s assume we have a high speed link between the two networks.
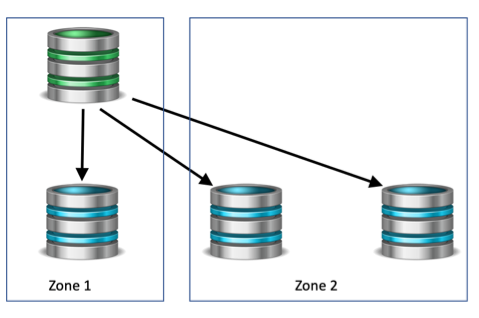 WRONG: Example 4-node cluster with an even number of nodes which is not recommendedWRONG: Example 4-node cluster with an even number of nodes which is not recommendedWRONG: Example 4-node cluster with an even number of nodes which is not recommended
WRONG: Example 4-node cluster with an even number of nodes which is not recommendedWRONG: Example 4-node cluster with an even number of nodes which is not recommendedWRONG: Example 4-node cluster with an even number of nodes which is not recommended
What would happen if the high speed link went offline between Zone 1 and Zone 2? The nodes on Zone 1 would contribute 2 votes, as well the nodes in Zone 2, causing a tie. This would result in a split-brain scenario, where both sides of the partition are active. The nodes in Zone 2 could initiate a failover and promote a node to master, while the master in Zone 1 does not know about the failover and remains a master. This cluster would have two masters, causing traffic to be routed now to both masters. Fortunately, Tungsten Clusters have split-brain detection and would take the entire cluster offline to protect the data.
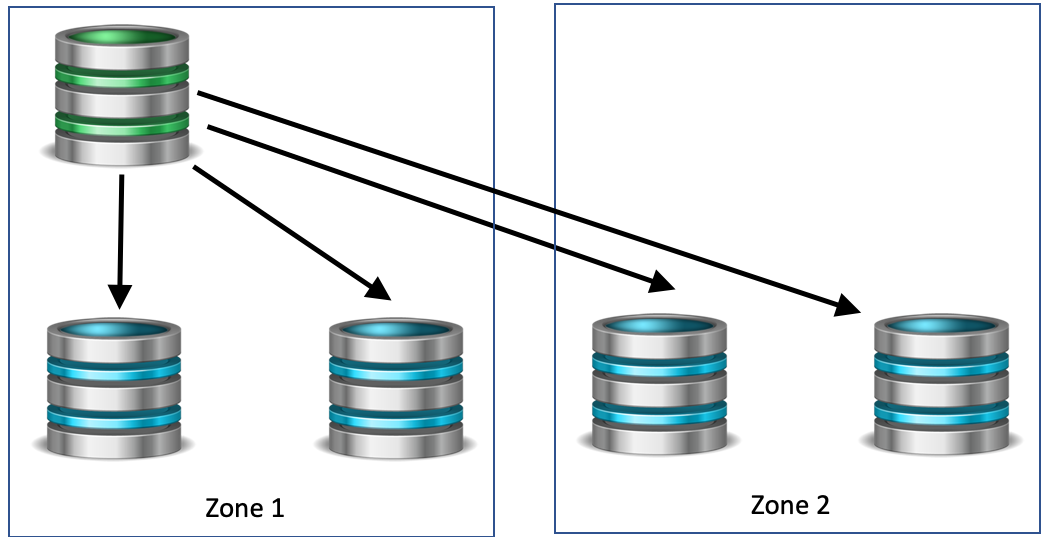
If instead we had an additional node in Zone 2, during a network partition there would be three votes to two, and failover would happen to Zone 2, with the members in Zone 1 being shunned. They can later be recovered as slaves when the high speed link is restored. Of course, the additional node could be in Zone 1, and in this case no failover would happen, and the nodes in zone 2 would be shunned.
That's how Tungsten Clustering keeps your data safe!

Comments
Roger (not verified)
Does the Split Brain happen
Wed, 06/03/2020 - 11:36Does the Split Brain happen only with different networks, like your example?
What if the nodes are in the same network?
Eric M. Stone, ...
Split Brain occurs whenever
Wed, 06/03/2020 - 12:58Split Brain occurs whenever two nodes are network-isolated, which can happen even on a LAN - perhaps the network port is down or switching was interrupted. the docs have more info:
https://docs.continuent.com/tungsten-clustering-6.1/operations-recovery-...
Add new comment