Summary
This blog post will explore the best practices for deploying Tungsten Clustering across Availability Zones.
When deploying a Tungsten Cluster into any cloud environment, the best availabilty is achieved by spreading the nodes amongst the various divisions provided by the cloud vendor. For example, AWS uses the concept of Availability Zones within Regions (AWS Docs: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-regions-availability-zones.html)
Each Region is a separate geographic area. Each Region has multiple, isolated locations known as Availability Zones.
Pros and Cons
Database Nodes
If all nodes are in the same Availability Zone (AZ), and that zone fails, then the entire cluster would be down as well. Intuitively, admins in search of uptime would place one node in each availability zone, thinking that was the ideal topology.
In fact, that topology is NOT ideal in terms of handling all of the edge cases.
What is the best topology for a 3-node cluster? At minimum, two nodes in AZ-a (the "key" AZ) with one of them running as master and one node in AZ-b.
Let's explore the failure scenarios:
| Scenario | a1-b1-c1 | a2-b1 | a2-b1-c1-d1 |
|---|---|---|---|
| All AZ's cannot communicate over the network | FailSafe-SHUN ALL Nodes | Cluster continues to operate normally, using 2 nodes in AZ-a | FailSafe-SHUN ALL Nodes |
| Loss of key AZ-a | Cluster continues to operate normally, using single nodes in AZ-b and AZ-c | FailSafe-SHUN in AZ-b due to no quorum majority, cluster down | Cluster continues to operate normally, using single nodes in AZ-b, AZ-c and AZ-d |
| Loss of AZ-b | Cluster continues to operate normally, using single nodes in AZ-a and AZ-c | Cluster continues to operate normally, using 2 nodes in AZ-a | Cluster continues to operate normally, using single nodes in AZ-a, AZ-b and AZ-d |
| Loss of AZ-b and AZ-c | FailSafe-SHUN in AZ-a due to no quorum majority, cluster down | Cluster continues to operate normally, using 2 nodes in AZ-a | Cluster continues to operate normally, using 2 nodes in AZ-a and a single node in AZ-d |
| Loss of key AZ-a and AZ-b | FailSafe-SHUN in AZ-c due to no quorum majority, cluster down | Cluster down, No available nodes | FailSafe-SHUN in AZ-c and AZ-d due to no quorum majority, cluster down |
While the Scenario "Loss of key AZ-a" allows two nodes to remain up in the a1-b1-c1 topology, that weighs less than the complete loss of the cluster in Scenario "All AZ's cannot communicate over the network".
The chance of losing two AZ's at the same time is low but still possible. To cover this case, add two more nodes in one or more additional AZ's for a total of five (must be an odd number of nodes for quorum purposes).
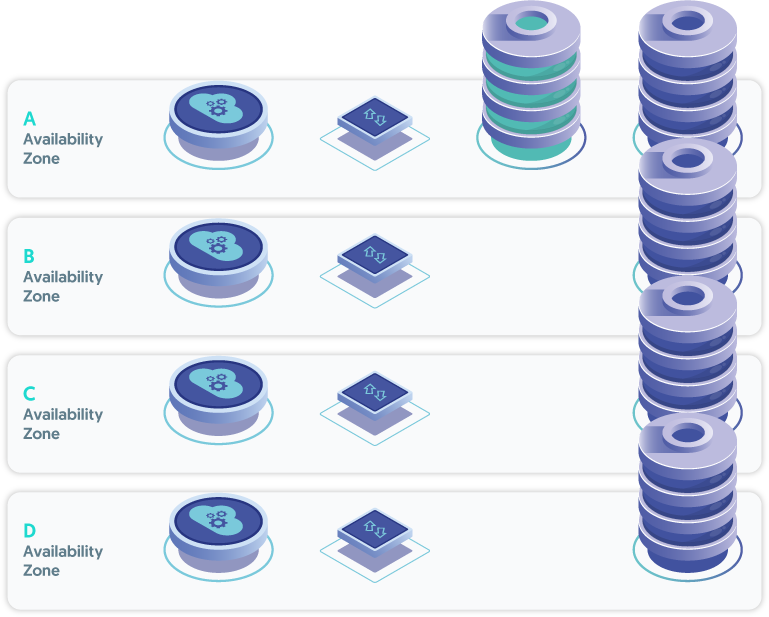
Please note that the master role moves between nodes, and it is possible that the database node in AZ-b would become the current master. In this case, you would need to manually switch back to a node in AZ-a during a selected period of low traffic.
Connector Nodes
Background
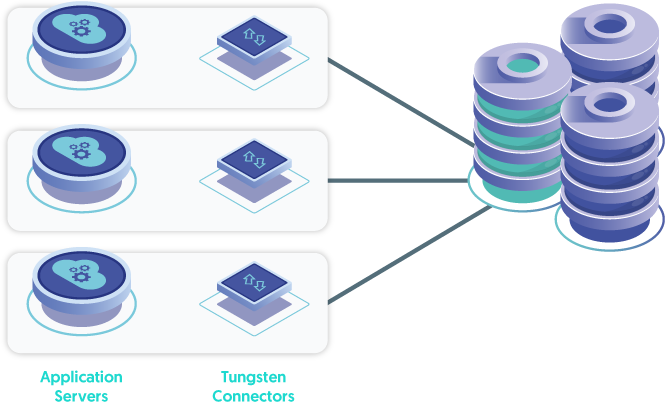
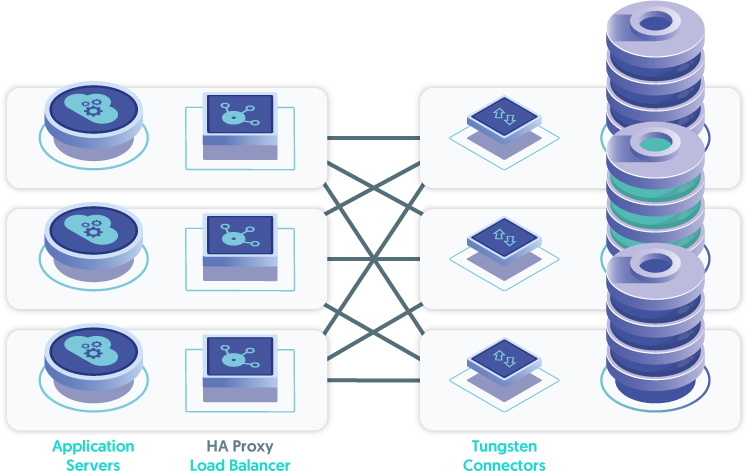
The ideal location for the Tungsten Connector (short: Connector - an intelligent MySQL Proxy) is directly on the application server itself, with multiple, load-balanced application servers - let's call that the "App-Local Connector Deployment".
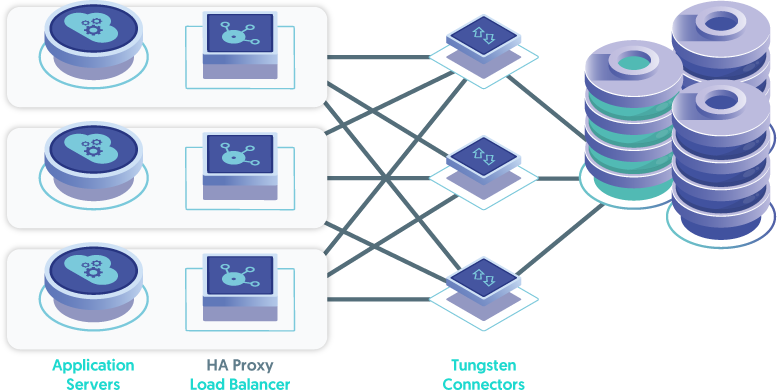
The next topology to consider after app-local would be the "Connector Farm deployment". This topology would have two or more hosts, each running the Connector, and some form of load balancer between the application servers and the Connector layer nodes. This is because the Connectors provide High Availability for the database layer, yet they themselves are not inherently fault-tolerant. A software load balancer (i.e. HA Proxy) can easily be installed on each application server to provide this functionality, or a hardware load balancer solution may be used as well.
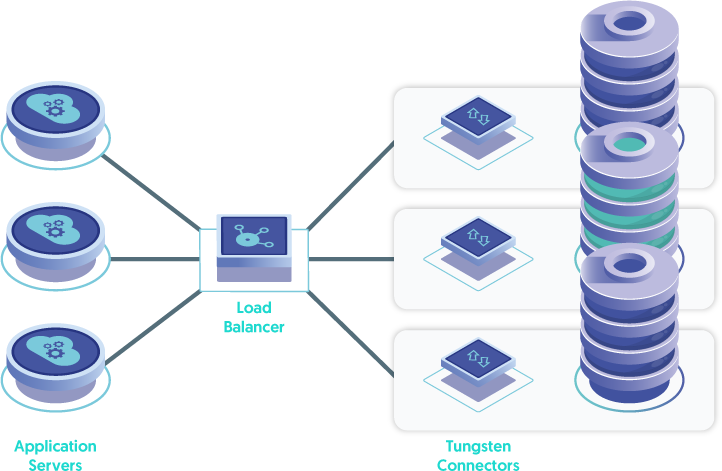
Lastly, the Connectors may be installed directly on the database nodes - the "DB-node Connector deployment". This is the least desirable solution, since it places additional load on the database servers in terms of CPU, network bandwidth and memory consumption. It also forces the database node to become a traffic router when requests for a write hit a Connector installed on a slave database node. This is far less than ideal.
Location versus Response Time
Now, let's examine each of these topologies in terms of response time and end-to-end performance. The placement of the Connectors in relationship to the nodes themselves is the key to the architecture.
For the sake of this discussion, all reads and writes will go to the master node in AZ-a. A future blog post will cover read-enabled slaves and how to improve performance using read/write splitting.
In the App-local topology, the location is based upon the location of the application servers. In this case, it would be ideal to have at least one located in the same AZ as the master node for the shortest round-trip time overall. For high availability, having an additional application server in AZ-b would work well.
In the case of a Connector Farm, the same would apply. Simply place one or more Connector nodes in AZ-a and at least one in AZ-b for the best performance and availability.
Lastly, in all cases, tune the load balancer in front of the application servers or Connector layer to prefer instances co-located with the master in AZ-a for the fastest end-to-end response times.
Conclusions
- For the best high-availability, place two database nodes in the same AZ, and a third in a different AZ.
- For the fastest response time end-to-end, place some of the connectors in the same AZ and the two nodes described above
- Ensure the load balancing is tuned to weight the Connector nodes in the key AZ.
- Click here for additional information in our online documentation...

Comments
Add new comment