Currently ranked 33rd on DB-Engines’ popularity ranking of database management systems (with a downwards trend), Amazon Redshift does have benefits for real-time data analytics on high volumes of data.
According to Amazon itself, Redshift is a data warehouse that makes it easy for users to gain new insights from all of their data. It enables users to query and combine exabytes of structured and semi-structured data across their data warehouse, operational database, and data lake using standard SQL.
As you’ll be aware, data analytics is a must-have business requirement nowadays; and you’ll also know that building an analytical data warehouse requires vast computing power to maintain performance and quick retrieval of data and results.
Traditional ETL methods can’t keep up with large volumes of data, and can require manual reprocessing when an error occurs. Running queries by record change date puts a load on your MySQL server and pollutes your cache.
Amazon Redshift has been providing scalable, quick-to-access analytics platforms for many years, but the question remains: how do you get the data from your existing datastore into Redshift for processing?
This blog looks at that question by providing some background information on Redshift replication as well as details on how to easily replicate from MySQL to Redshift.
Why Amazon Redshift
Redshift presents an advantage for analytics in that it is able to join multiple data sources, such as for example analytic events coming from an online application with customer data stored in a MySQL database.
For that type of scenario, Redshift offers a fully managed cloud solution for modern data warehouses with a vast parallel processing data warehouse architecture using a columnar data store. In other words, it can deal with large amounts of data enabling faster performance (regardless of the amount of data that needs analyzing).
Why Replicate From MySQL to Amazon Redshift
As established earlier, for real-time data analytics on high volumes of data, Redshift does have some real benefits as it is built to handle large scale data analytics.
There are any number of scenarios where replication from MySQL to Redshift may be needed, including some of the following:
- Creating a replication pipeline that replicates tables and data from MySQL to Redshift.
- Having multiple replicas of data in several different types of data stores where different parts of an application have different requirements from these data stores.
- Needing to join multiple data sources: some users look to move to Redshift in order to join and intersect multiple data sources.
- Requiring increased analytical queries performance: MySQL is optimized to deal with a relatively small number of records, so when it comes to analyzing large amounts of data, analytical queries tend to underperform in MySQL, which can cause MySQL database overloading and blocking.
Tungsten Replicator (AMI) for Amazon Redshift
Wouldn’t it be great if you could replicate your data in real time, filter on the tables and schemas you need, all without putting any extra load on your MySQL server? Wouldn’t it also be great if schema changes just flowed through from MySQL to Amazon RedShift, without intervention on your part? That’s where Tungsten Replicator (AMI) comes in.
Tungsten replicator is a great tool when it comes to replication of data with heterogeneous (or homogeneous) data sources as it’s easy to configure and operate. It includes support for parallel replication, and advanced topologies such as fan-in and multi-master, and can be used efficiently in cross-site deployments.
It provides high-performance and improved replication functionality over the native MySQL replication solution and into a range of targets / databases, such as AWS RedShift of course… as well as MySQL (all versions), Oracle, Vertica, Hadoop, ClickHouse, Kafka, MongoDB & PostgreSQL.
In short, it is the most advanced heterogeneous replication solution for MySQL, MariaDB & Percona Server, including Amazon RDS MySQL and Amazon Aurora. It’s available as an AMI and can be accessed via AWS.
First off …
Some Terminology
There are three major components in Tungsten Replicator that users need to know about in particular:
- Extractor / Primary Service
- Transaction History Log (THL)
- Applier / Replica Service
Extractor / Primary Service
The extractor component reads data from MySQL’s binary log and writes that information into the Transaction History Log (THL).
Transaction History Log (THL)
The Transaction History Log (THL) acts as a translator between two different data sources. It stores transactional data from different data servers in a universal format using the replicator service acting as a primary, that could then be processed to the applier / replica service.
Applier / Replica Service
All the raw row-data recorded on the THL logs is re-assembled or constructed into another format such as JSON or BSON, or external CSV formats that enable the data to be loaded in bulk batches into a variety of different targets.
Statement information is therefore not supported for heterogeneous deployments and it is mandatory that the binary log format on MySQL is ROW.
How Replication to Amazon Redshift Works
Option 1: Local Install
The extractor reads directly from the MySQL binary logs to extract transactions. This is the default.
Option 2: Remote Install
The extractor gets MySQL transactional data remotely via the MySQL Remote Replication Protocol (this is also how we extract from RDS/Aurora in Amazon).
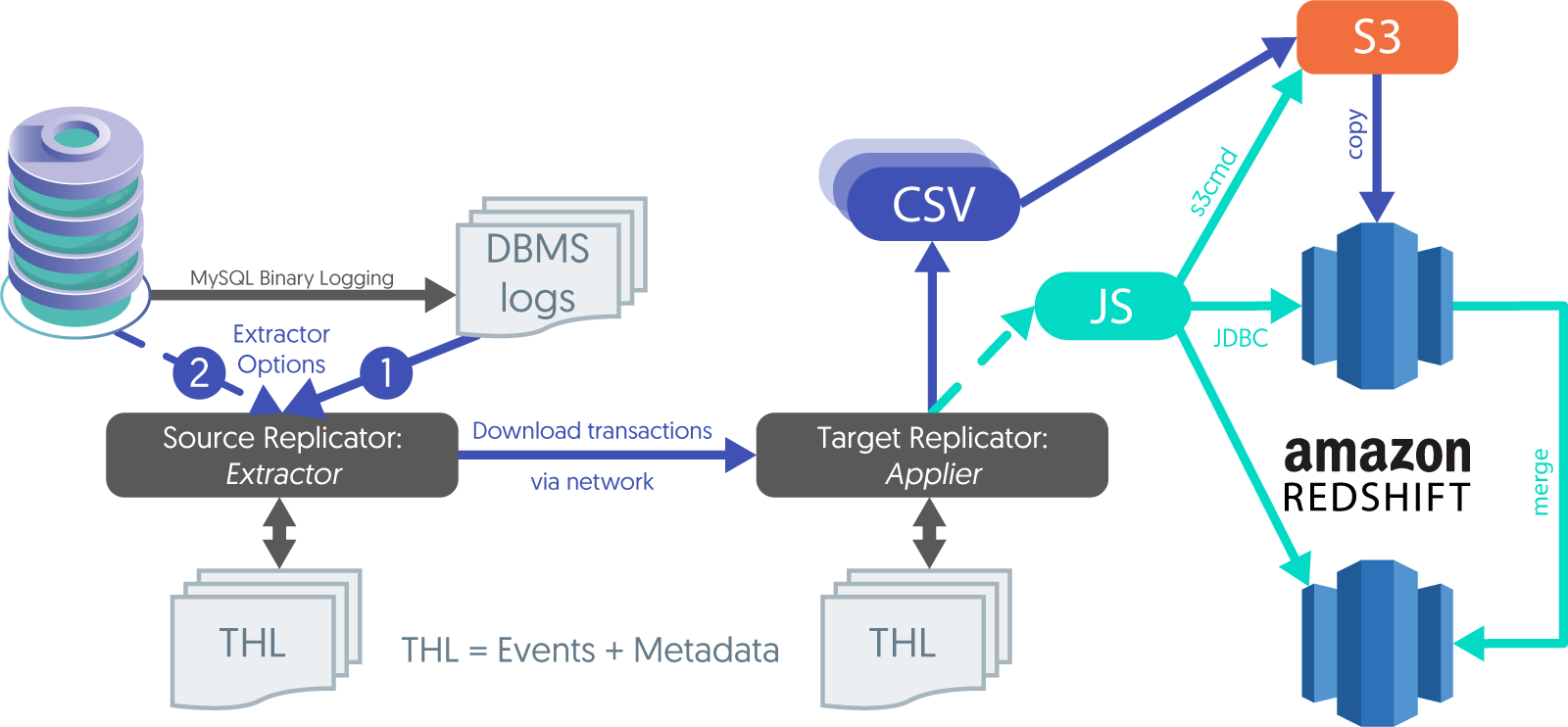
Flow of Transactional Data to Amazon Redshift
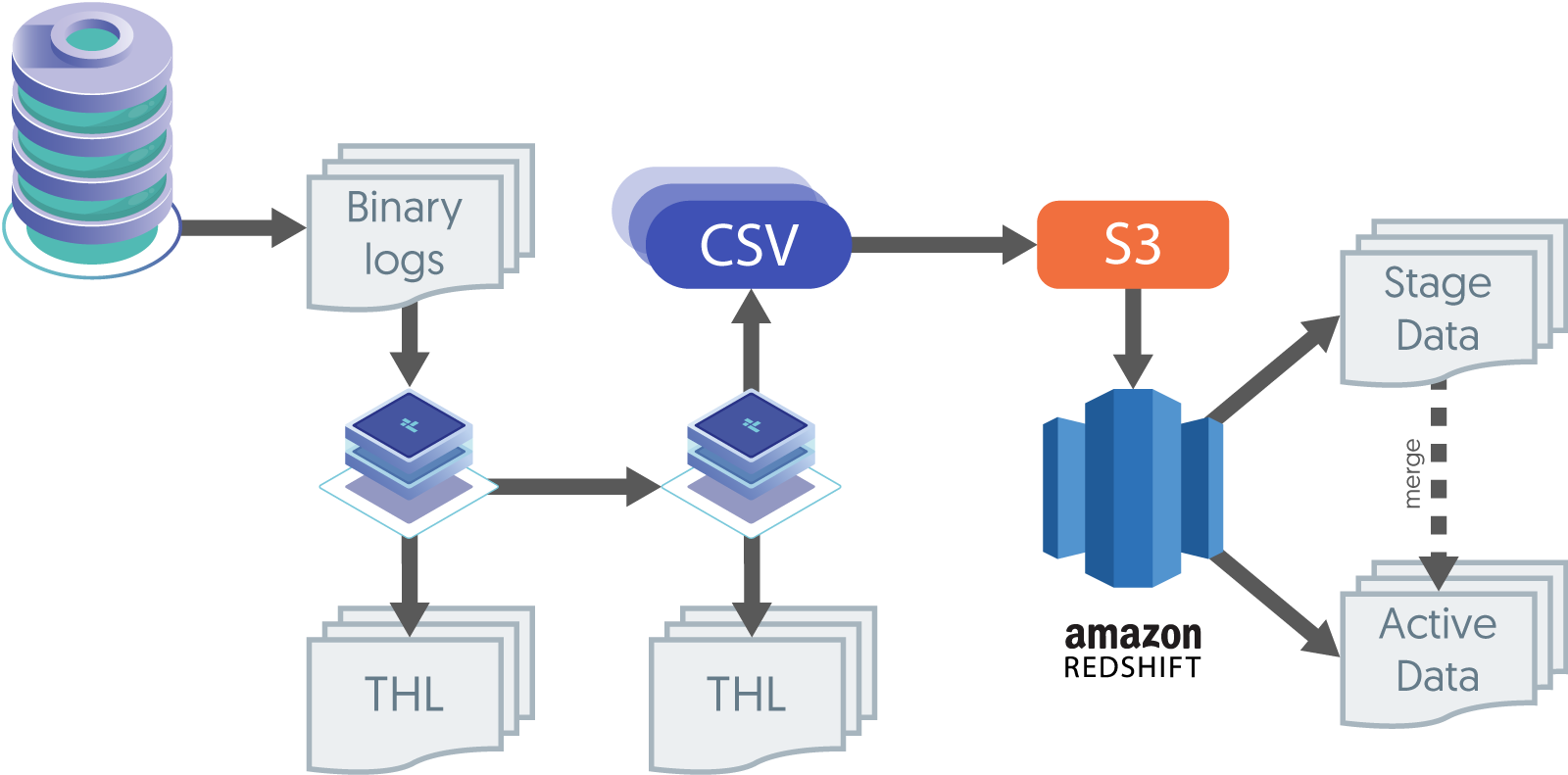
The graphic below shows how transactions are uploaded to S3, then loaded into staging tables, and then merged into the production tables.
How to Get Started With the Tungsten Replicator AMI
Getting started with the 14-Day free trial
Users can try one instance of each type of the AMI for free for 14 days to get them started (AWS infrastructure charges still apply).

Please note that free trials will automatically convert to a paid hourly subscription upon expiration and the following then applies in the case of Redshift targets.
Replicate from AWS Aurora, AWS RDS MySQL, MySQL, MariaDB & Percona Server to Amazon Redshift from as little as $0.60/hour
With Tungsten Replicator (AMI) on AWS, users can replicate GB's of data from as little as $60c/hour:
- Go to the AWS Marketplace, and search for Tungsten, or click here.
- Choose and Subscribe to the Tungsten Replicator for MySQL Source Extraction.
- Choose and Subscribe to the target Tungsten Replicator AMI of your choice.
- Pay by the hour.
- When launched, the host will have all the prerequisites in place and a simple "wizard" runs on first launch and asks the user questions about the source and/or target and then configures it all for them.

Watch the Getting Started Walkthrough
Our colleague Chris Parker recorded this handy walk-through on how to get started with the Tungsten Replicator AMI if you need some tips & tricks.

Extraction and Appliers
Below you’ll find the full listing of extractors and appliers that are available with Tungsten Replicator.
Replication Extraction from Operational Databases
- MySQL (all versions, on-premises and in the cloud)
- MariaDB (all versions, on-premises and in the cloud)
- Percona Server (all versions, on-premises and in the cloud)
- AWS Aurora
- AWS RDS MySQL
- Azure MySQL
- Google Cloud SQL
Available Replication Target Databases
Do give Tungsten Replicator AMI a try and let us know how you get on or if you have any questions by commenting below!
Related Blogs
Check out our related blogs if you’re (also) working with these databases / platforms:
- Vertica: Real-Time MySQL Analytics — How to Replicate Data in Real-Time from MySQL, MariaDB or Percona Server to Vertica
- PostgreSQL: How Replication to PostgreSQL Works: Replicating Data in Real-Time from MySQL, MariaDB or Percona Server to PostgreSQL
- Kafka: How Replication Between MySQL & Kafka Works: Replicating Data in Real-Time from MySQL, MariaDB or Percona Server to Kafka
- MongoDB: How to Replicate from MySQL to MongoDB (incl. MongoDB Atlas)
- Hadoop: Real-Time Big Data Analytics: How to Replicate from MySQL to Hadoop

Comments
Add new comment