How to Handle More Work: Go Out
Scalability is necessary to keep your database from crumbling under increased traffic. A scalable database must be able to handle larger data sets and more queries per second (both read and write), and the architecture must support these higher workloads seamlessly and efficiently.
One way to scale is to add resources to your box or resize to a bigger one; this strategy is called “vertical scaling” or “scaling up.”
The issues with scaling up are you hit your head on a hard ceiling, as the cost of adding high-end hardware quickly goes up, and there are diminishing returns as you add more computing resources.
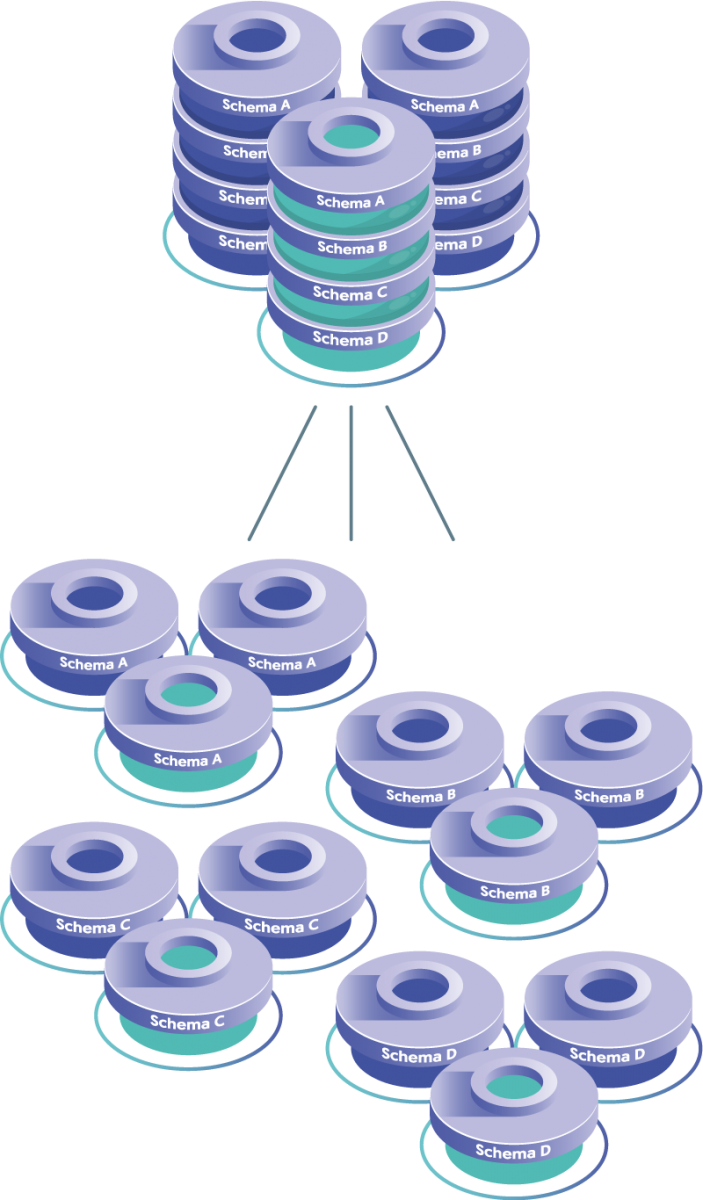
Thus, you may “scale horizontally,” aka “scale out,” by adding additional boxes and connecting them so that they act as one. Below (on the left) is an example of a single cluster with multiple schemas filling up big machines; the image shows how you may distribute (by schema) a single cluster into multiple smaller commodity hardware clusters, for near infinite scalability.
This scaling out strategy is employed for enterprise business-critical applications because you may theoretically add as many servers as you wish and more importantly, scaling out may provide the additional benefit of higher availability. Downtime - such as a hardware failure or planned maintenance - can’t make up for all the scalability in the world! Hence why so much time is spent creating a system of tightly-integrated, distributed machines that hopefully isn’t too complicated to set up, troubleshoot and manage.
Sharding and Pod Architecture
But how do you distribute a relational database across multiple machines? If the dataset and throughput are significant enough, you need a way to distribute the dataset so that no single database server is required to contain all the data. Enter: Sharding. Sharding is a method for splitting and distributing data across multiple machines.
Pod architecture is a simple type of sharding that works well for very high volume, high throughput SaaS applications. One benefit of it is it’s easy to manage and highly available.
Using pod architecture, the data is not necessarily “sharded” so much as just organized by database schema into different “pods,” or unique standalone clusters. In SaaS organizations the database schema usually represents a customer with its own pod or a shared pod with other customer database schemas.
Within a pod, you may have many replica nodes, limited only by environmental resources (such as network bandwidth and node CPU) and distribute the workload across them all. There are many ways to balance the load across the nodes; for example, you may reduce or eliminate the read-load from the Primary and spread the burden across the Replicas, which then frees the Primary node to focus exclusively on the write-load. This basic load balancing technique increases overall read and write throughput.
We have SaaS customers handling up to 5 TB of OLTP application data in high-throughput environments using pod architecture; they use Tungsten Clustering so their MySQL data can be highly available and cost-effectively scalable. As they grow in customer traffic and data volume, they just keep adding as many nodes and pods as needed.
If you are dealing with a dataset where it doesn’t make sense to organize tables into pod-shards, then pod architecture may not work for you. You may want to go with another sharding technique that allows you to shard by a different defined range of data. Smaller shards may enable greater scalability but are not necessarily “made for SaaS” per-se and can be very complicated to manage, so you need to assess what makes sense for your environment and requirements. You may also consider a different cluster architecture if you need cost-effective scalability, but not so much that it necessitates sharding. Parallel threading and load balancing may provide plenty of scalability for your needs. Note that while Scalability is one reason to use pod architecture, the highest priority with any Tungsten solution is Availability.
Conclusion
At Continuent, we love pushing limits; we are constantly extending the uptime of MySQL, measured in years for many of our customers. Tungsten Clustering is used to run business-critical applications on MySQL, MariaDB or Percona Server for MySQL - continuously and globally. It is the only geo-scale active/active capable clustering available for MySQL databases.
As a final note, if you’re looking to achieve scalability by using a microservices architecture, you may be in luck because Tungsten works well with microservices and is about to get better! Stay tuned and reach out if you’re interested in a demo or to test Tungsten Clustering in your environment.

Comments
Add new comment