Yes, Geo-Deployed MySQL Active/Active IS Possible
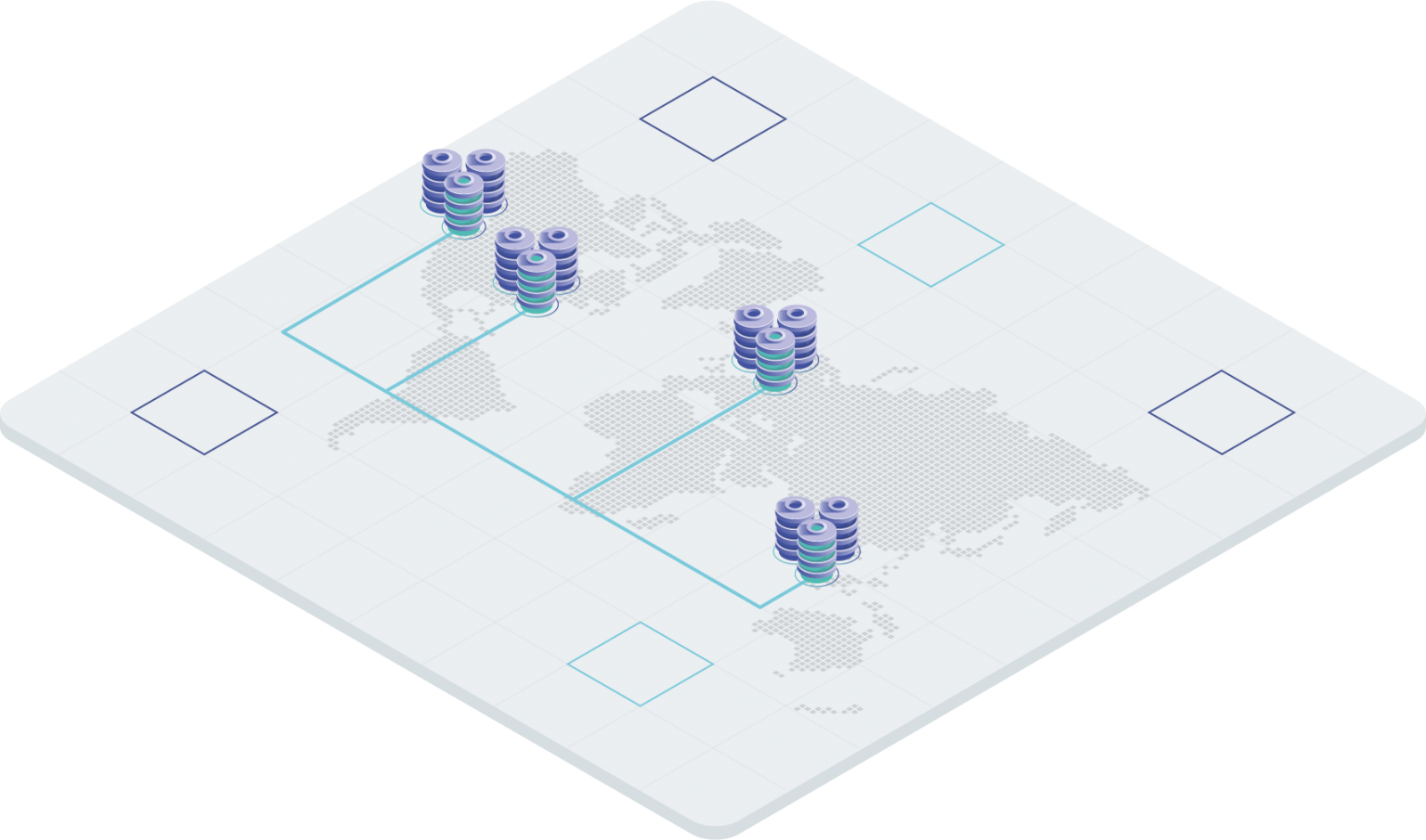
We are proud to deploy MySQL Active/Active clusters at Geo-scale. There are several capable MySQL Cluster products available; however, just Tungsten Clustering easily scales clusters over long distances. You can deploy an Active (read/write) cluster in Florida. Then add another Active cluster in California to service customers on the West Coast. You may expand the topology with another Active cluster in the UK. Each cluster is actively taking traffic, and replication is happening between all of the clusters. Tungsten Clustering is able to do this by using Tungsten Replicator, which employs asynchronous replication. Only asynchronous replication can support replication over long distances without slowing down the applications.
Inherent with asynchronous replication and Active/Active topologies is the possibility of replication conflicts or collisions. However, with some basic planning and tools, we can minimize the chances for conflicts. How we avoid conflicts ultimately depends on the applications and use cases, but below are a few pointers to get you started.
The Most Basic and Effective Technique: Offsets
We can take advantage of MySQL’s auto-increment auto-increment-offset and auto-increment-increment parameters to guarantee that the primary key, if defined as integer with auto-increment enabled on that field, will be unique across the entire topology without the chance for collision. For instance, for our 3 cluster topology, we can add into my.cnf:
# servers in Florida
auto-increment-increment = 3
auto-increment-offset = 1
# servers in California
auto-increment-increment = 3
auto-increment-offset = 2
# servers in UK
auto-increment-increment = 3
auto-increment-offset = 3
So now inserts in Florida will have primary keys of 1,4,7…. California will have 2,5,8… and UK will have 3,6,9…
| Primary Key Value | Source of Data |
|---|---|
| 1 | Florida |
| 2 | California |
| 3 | UK |
| 4 | Florida |
| 5 | California |
| 6 | UK |
| 7 | Florida |
| 8 | California |
With this technique, the primary keys mesh perfectly without conflicts.
Affinity
While the offset technique helps to avoid conflicts on Inserts, the situation is a bit more difficult with Updates. This is where affinity can help. We simply route the end user to the closest cluster for each request. Many DNS services already offer this, which will bind the user to a single cluster. So for instance, since I am in Florida, I will be bound to the Florida cluster whether I use my computer or phone (or both at the same time!). This guarantees that multiple sessions into my account or data will always be processed on the cluster closest to me (let’s say I’m using my account with my computer and phone at the same time). Without affinity, one device may be routed to the Florida cluster, while a second device to the California cluster. This could cause conflicts, as records could be updated in both clusters at relatively the same time. Affinity by location is fairly easy to implement using DNS, and doesn’t require any change to the application.
We can take affinity a step further though. What if I take a trip to Europe? Affinity, as described above, works great, as I will be routed to the UK cluster and performance will be great. But what if I'm using my account and have an issue with an online order, and I need to call Customer Service back in the USA? We can build hints into our application. First, we create a connection pool on each site for all other sites. In our example, our UK site will have a local connection pool (default), and California and Florida connection pools. Suppose I am modifying my account on the UK cluster, while customer service is potentially modifying my account in the California cluster, which now increases the risk of a conflict. At this point our application can leverage the connection pools. Whenever I log onto my account, in addition to a timestamp of my login, the cluster that I’m routed to is recorded into the database as well (in this case, UK). If Customer Service needs to help me, the app will read my last location and choose the connection pool based on my last location. So, Customer Service on the west coast will route all writes to the UK via the connection pool (but reads can still happen locally!). Therefore, all changes to my account are now happening in a single cluster and replicated, further reducing the chance of conflict.
Constraints and Auto-Retry
Distributed databases have a property called eventual consistency. A simple way to describe this is that while the database is active, there’s no guarantee that each copy of the data will be the same across all sites. However, if the database is at rest, eventually all the data will be the same across all sites. Almost every distributed database has eventual consistency to some extent.
Multi-primary clusters spread across slow networks have the possibility of transactions being played slightly out of order. This usually is not an issue, especially when affinity is used. However, when affinity is not in use and there are constraints in the schema to force data consistency, the replication can stall due to an error. Let’s look at an example:
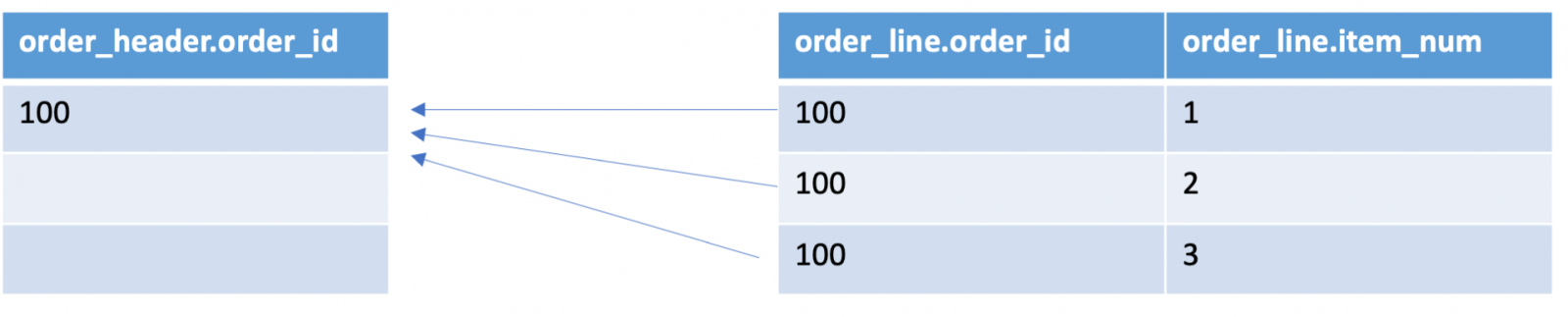
I would like to place an order with 3 items on it. My order number will be 100, and each item in my order is numbered 1, 2, 3. My order_line table has a constraint that the order_id must exist in the order_header table, which prevents orphaned order_lines.
Without affinity, it’s possible the transaction to write order_header will occur in Florida, while the order_line transactions will be directed to California. This usually isn’t a problem, unless there is a slight lag between sites. Then for a split second, my order_header will be Florida, but due to replication lag, will not be available in California:
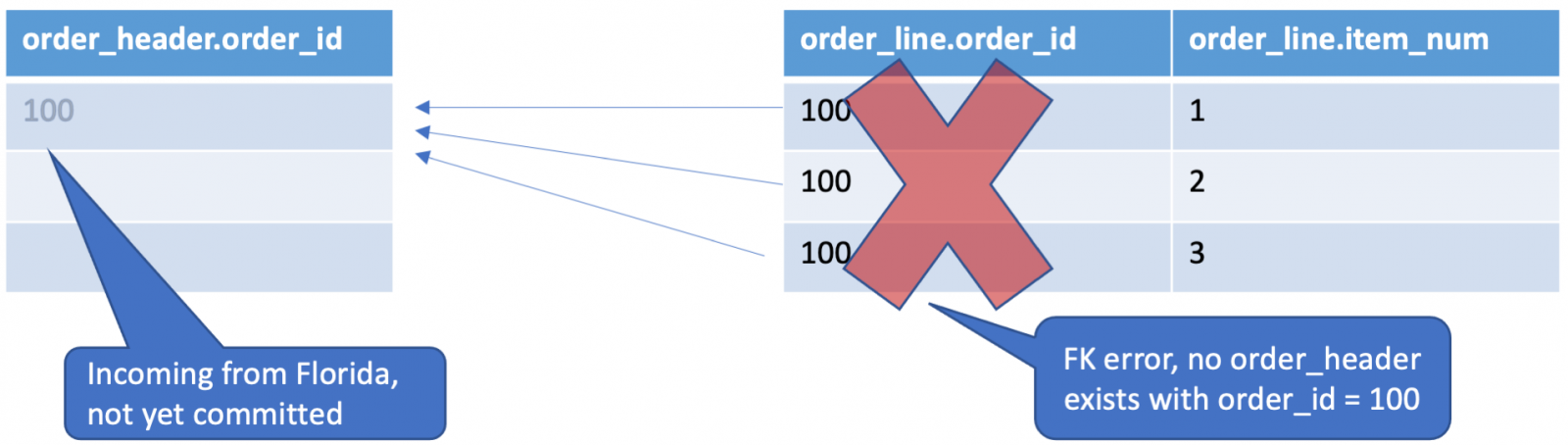
With two replication streams writing to a host, a couple of millisecond lag from Florida to California, will cause the replication service that was writing the order_lines to error and go offline. Fortunately, there are 2 simple ways to address this:
- Simply remove the constraints from the tables and let eventual consistency do the work. The order_lines will be committed, and a few milliseconds later, the order_header
- Removing constraints isn’t always an option. Therefore, the Tungsten Replicator can simply retry failing transactions. The options are:
auto-recovery-delay-interval=5s auto-recovery-max-attempts=3 auto-recovery-reset-interval=30sThe first option specifies the delay to retry, and the second option is the number of times the replicator will retry before it gives up. So in our example, the replicator would encounter an error due to the foreign key constraint, and then retry 5 seconds later, which by that time our order_header is committed to the database.
The last option tells the Replicator how long to delay before autorecovery is deemed to have succeeded. In other words, this is the amount of time that the Replicator must be in the ONLINE state before the replicator will mark the autorecovery procedure as succeeded. For servers with very large transactions, this value should be increased to allow the transactions to be applied successfully.
Summary
Deploying Active/Active clusters at geo-scale is not only possible with Tungsten Clustering, it is a powerful topology that gives the end-user a robust application experience whenever they are in the world. With some advanced planning, we can reduce or avoid conflicts altogether using auto-increment offsets, affinity, and understanding the database concept of eventual consistency.
One final bonus tip which applies to any topology but especially to Active/Active topologies, is to use small transaction sizes. Smaller transactions commit more quickly, can be rolled back more quickly, and are more robust when doing any type of replication.
Reach out to us if you would like to learn more about active/active geo-clustering for MySQL or MariaDB.

Comments
Add new comment