The main reason for clustering business-critical MySQL is for availability, per our definition:
Availability means the database service operates continuously with good performance.
That’s what I want to discuss in this blog - two types of replication technology for highly available clustered, distributed MySQL systems. If you're interested in learning about more than just async vs sync replication technologies, please see this blog: "Comparing Replication Technologies for MySQL."
First of all, what qualifies me to talk about replication and clustering? I’m a Customer Success Manager serving some long-time happy companies like ProductIP and Riot Games (check out their AWS:reInvent talk), and I work closely with Continuent engineers who develop infrastructure-agnostic (on-prem, hybrid-cloud, cloud, multi-cloud, etc.) MySQL, MariaDB, and Percona MySQL geographically-distributed high availability and disaster recovery solutions. We focus on business continuity and best-in-class enterprise 24/7 support; and each year since 2004, we’ve safeguarded billions of dollars of combined revenue for SaaS and other industries.
We aim to be an objective, unbiased resource, so anyone who asks for help with open source databases like native MySQL, MariaDB or Percona MySQL may get the best out of them.
One common type of replication known as “synchronous” aims to update all database servers at the same time, keeping replication operations tightly-coupled with database operations to ensure consistency. In theory this would be ideal, but in practice there are issues with synchronous replication, as various articles such as this about maintaining consistency and this about avoiding performance loss when abating stale reads.
Why is this? The Codership’s Galera website explains:
[With synchronous replication] any increase in the number of nodes leads to an exponential growth in the transaction response times and in the probability of conflicts and deadlock rates.

Used in Codership’s Galera and its variants (MariaDB Galera and Percona XtraDB Cluster) synchronous replication consists of the following steps (not necessarily in this order):
- Apply - the cost is the size of the transaction (the same for any type of replication)
- Replicate - the cost is ~roundtrip latency to the furthest node
- Certification - the cost is based on the number of keys or number of rows
- Commit - finish the transaction (not really any cost)
The certification process checks if the writeset can be applied to all nodes before committing and giving control back to the application. The certification process helps with performance but as the Galera website states, the tradeoff between consistency and performance for synchronous solutions remains a steep challenge:
For this reason, asynchronous replication remains the dominant replication protocol for database performance, scalability and availability. Widely adopted open source databases, such as MySQL and PostgreSQL only provide asynchronous replication solutions.
As a side note, the team behind Galera used to work for Continuent. Galera has its roots in Continuent’s m/cluster solution which we abandoned in 2006. At its best, m/cluster was (and Galera is) great. But at its worst it is really bad. You just need to understand the use case and pick the solution based on that.
Continuent chose to offer high-available geographically distributed MySQL clusters that one can run in any environment, on-premises and in the cloud, also hybrid-cloud and multi-region, multi-cloud configurations.
So for MySQL performance especially over WAN (wide-area-network), Continuent Tungsten chose asynchronous replication. For more details about why, check out this blog about replication technologies from Customer Success Director, Americas, Matt Lang.
Continuent’s clustering solution uses Tungsten Replicator which is also used on its own because it can:
- Replicate from MySQL to various targets such as MongoDB and Vertica, replacing ETL.
- Change, format, and filter information in-flight.
- Be stopped, paused, and restarted without losing or skipping data.
- Replicate from a cluster or multiple sources (fan-in replication) and to multiple targets (fan-out replication) for backups, big data analytics, reporting, etc.
- Replicate data continuously and at high speed.
The stages in Tungsten replication begin after commit and giving control back to the application, providing the greatest responsiveness. Stay tuned for another blog article about the Tungsten replicator pipeline stages!
With respect to performance, nodes in a cluster can switch roles when there’s a reason to automatically failover. The Tungsten Proxy (aka Tungsten Connector), working in conjunction with the Tungsten Manager, keeps the database service available and prevents lost connections but it can also route reads and writes to different nodes based on different settings to maintain optimal performance; for example, it can inspect nodes to see if it has up-to-date and avoid stale reads. The Tungsten Proxy can also load balance reads across replicas utilizing several built in algorithms.
The power is that the Replicator, Manager, and Proxy (aka Connector) were designed to work together to make the Tungsten Clustering solution greater than the sum of its parts!
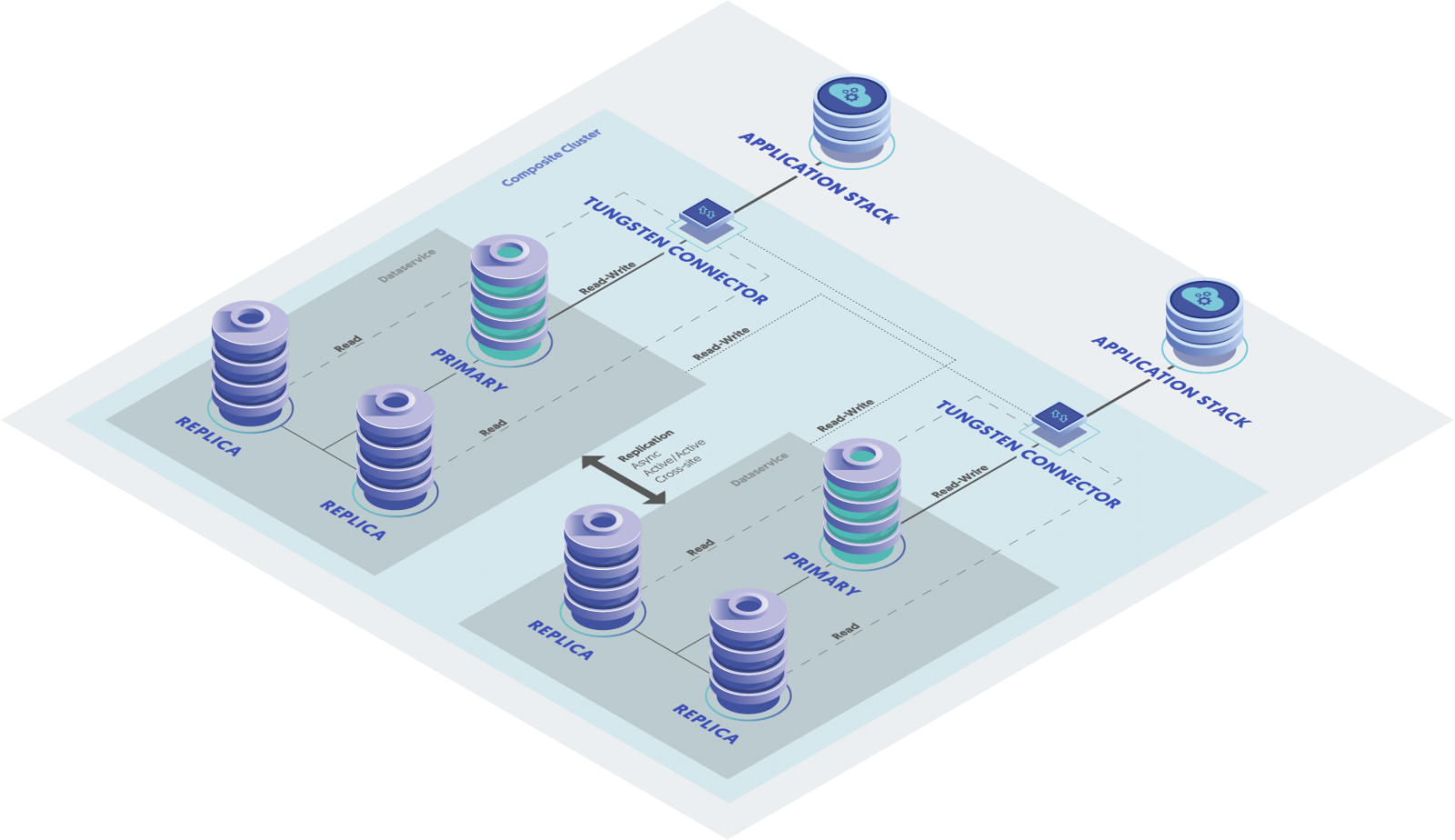
I hope you learned something about the difference between asynchronous versus synchronous replication for MySQL clusters! Feel free to follow us on Linkedin or Twitter to learn more, or reach out to start a conversation about your MySQL environment and requirements!

Comments
Add new comment