Tungsten Distributed Datasource Groups (DDG): More Power Than Ever
Tungsten clustering supports a variety of topologies, each with unique characteristics.
Today we introduce yet another compelling topology for your consideration: Tungsten Distributed Datasource Groups, with the new ability to failover automatically between Regions or Datacenters.
Distributed Datasource Groups: Why?
With geo-scaling, where we have assets in more than one physical region or datacenter, we offer a word salad of options: CAP, CAA, DAA and MSAA.
In the past, getting the “holy grail” of Active-Passive database clustering with automatic failover has not seemed possible, due to limitations in older versions of the Java jGroups library which the managers depend upon for communications. With the latest version of jGroups, we are now able to deliver upon the dream and provide automatic failover between Regions or Datacenters.
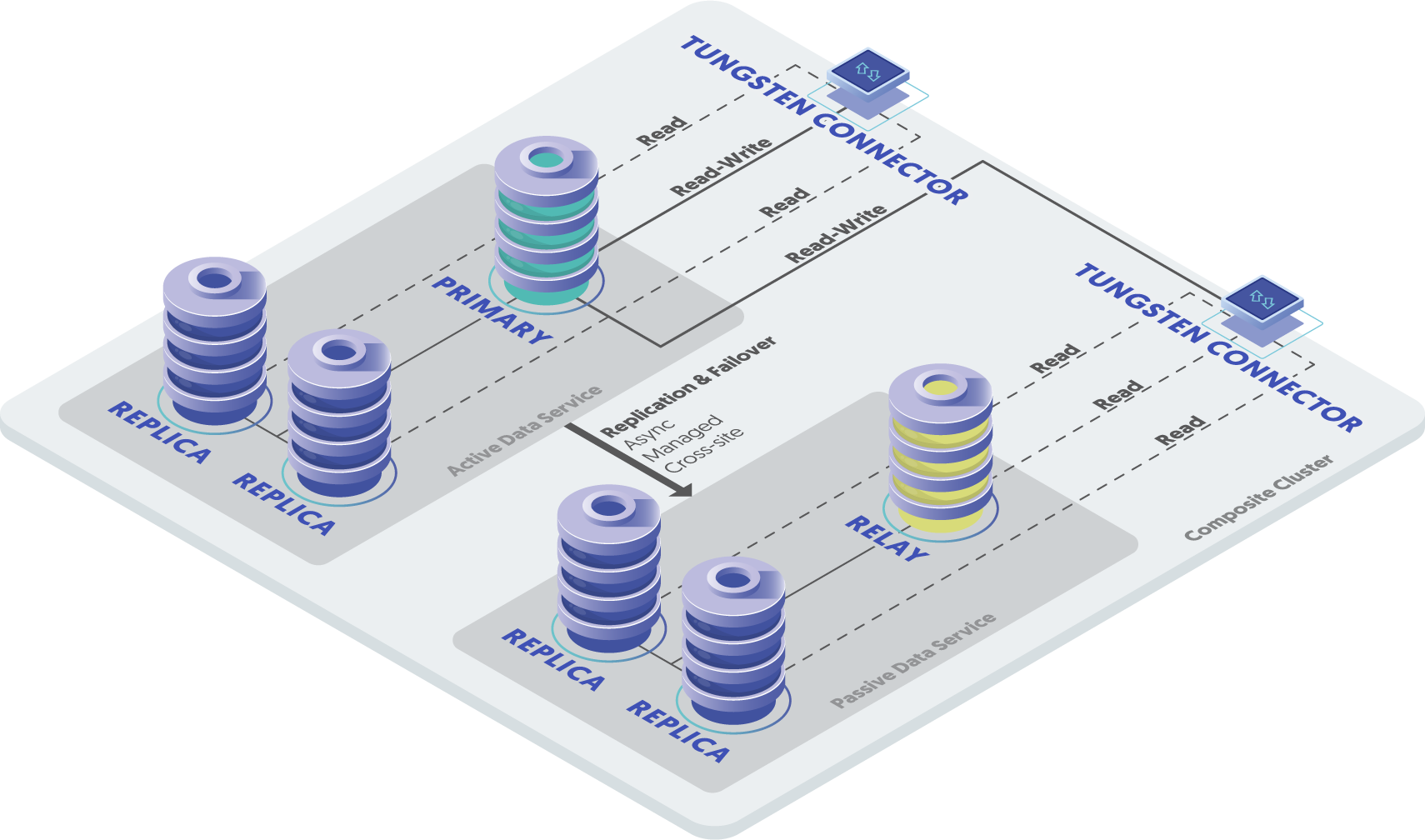
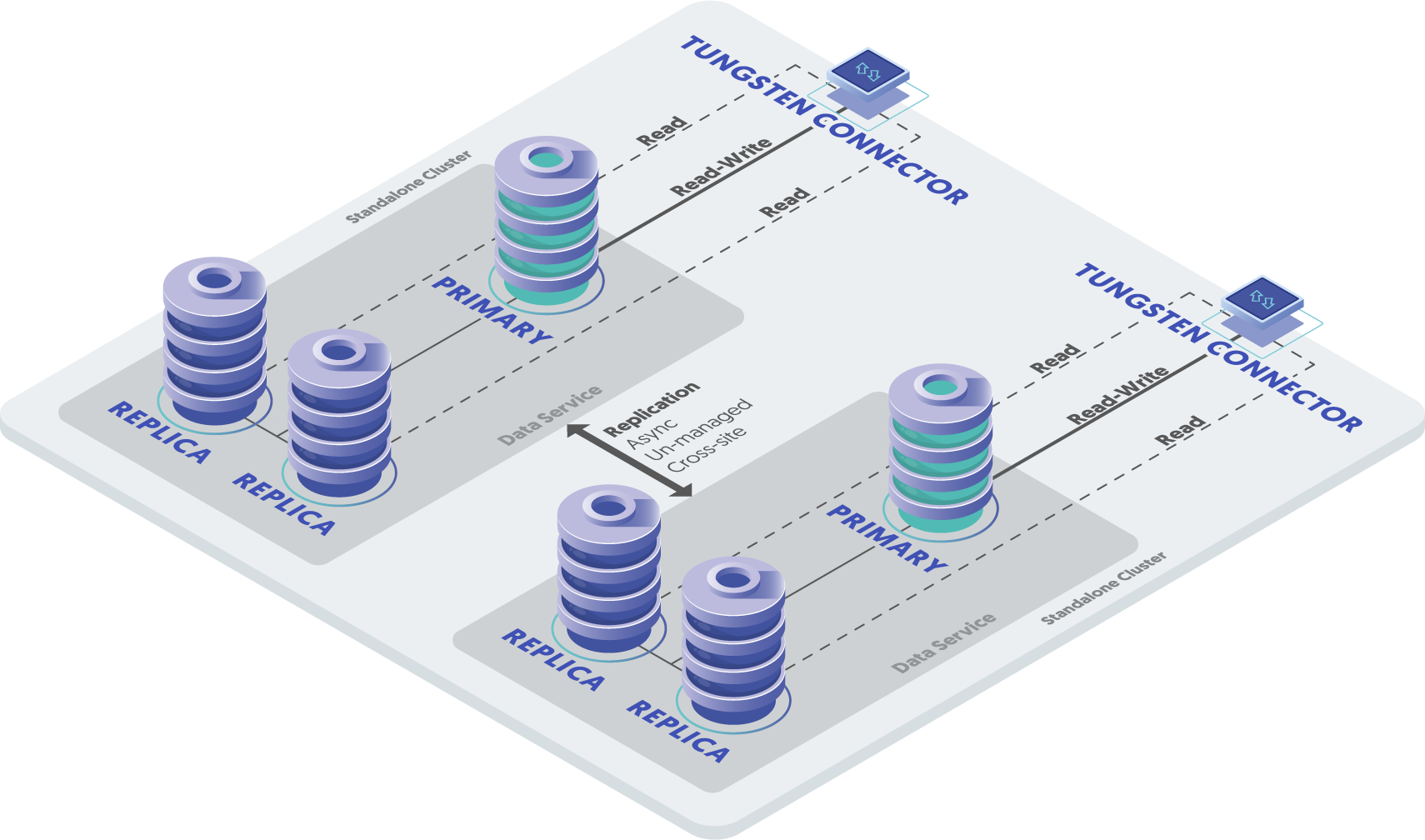
With our Composite Active-Passive clusters, there is one writable Primary, which reduces complexity considerably, but failover between Regions/Datacenters is manual.
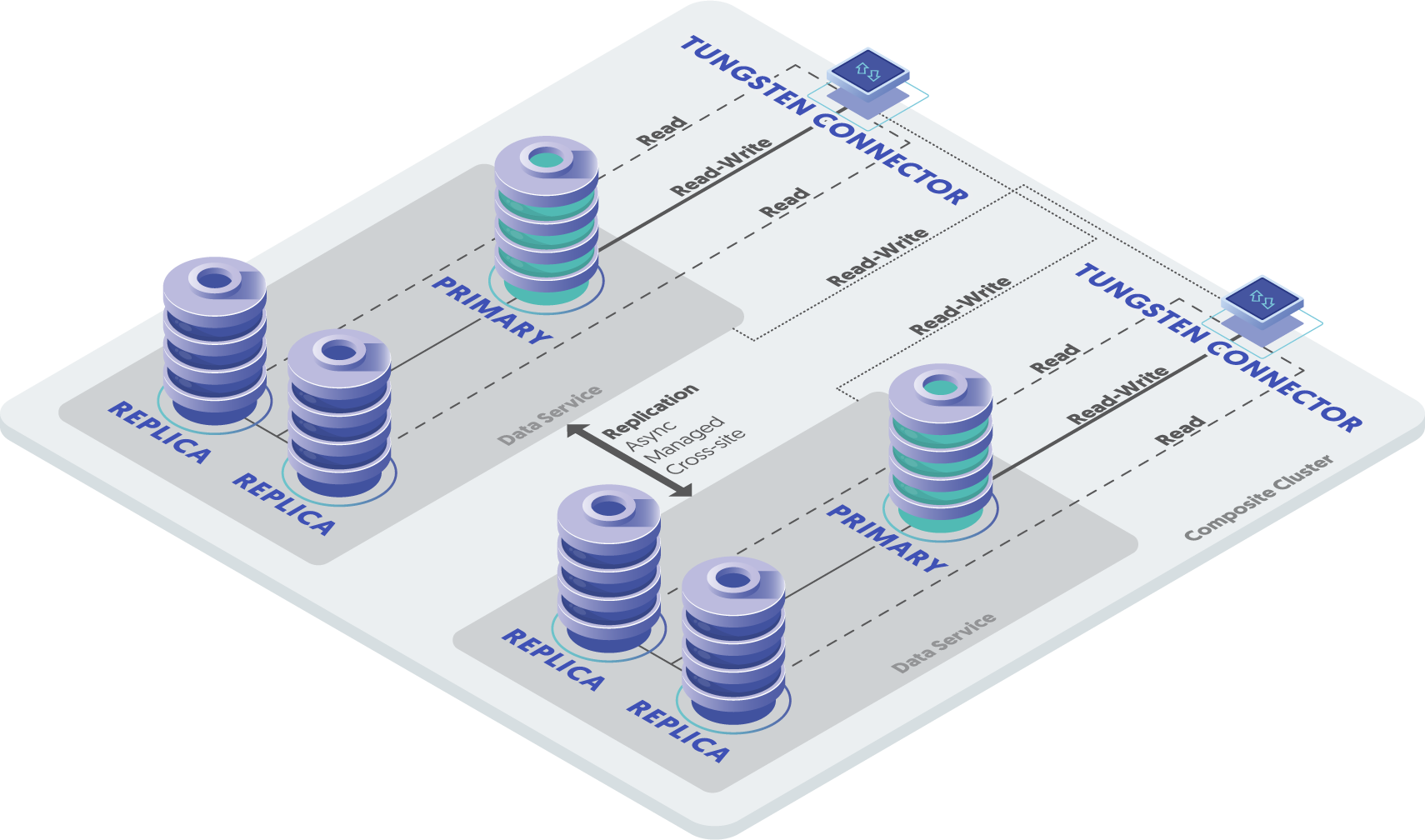
With our Composite Active-Active, Dynamic Active-Active and Multi-Site Active-Active topologies, there is no need for automatic failover, but the complexity is much higher because of the multiple replication services, resulting in a higher TCO. Also, in these topologies ROW-based replication is required, resulting in a greater overhead.
|
|
|
|
For a comparison of the existing topologies referenced here, please read the De-Mystifying Tungsten Cluster Topologies, Part 3: CAP vs. CAA vs. DAA blog post.
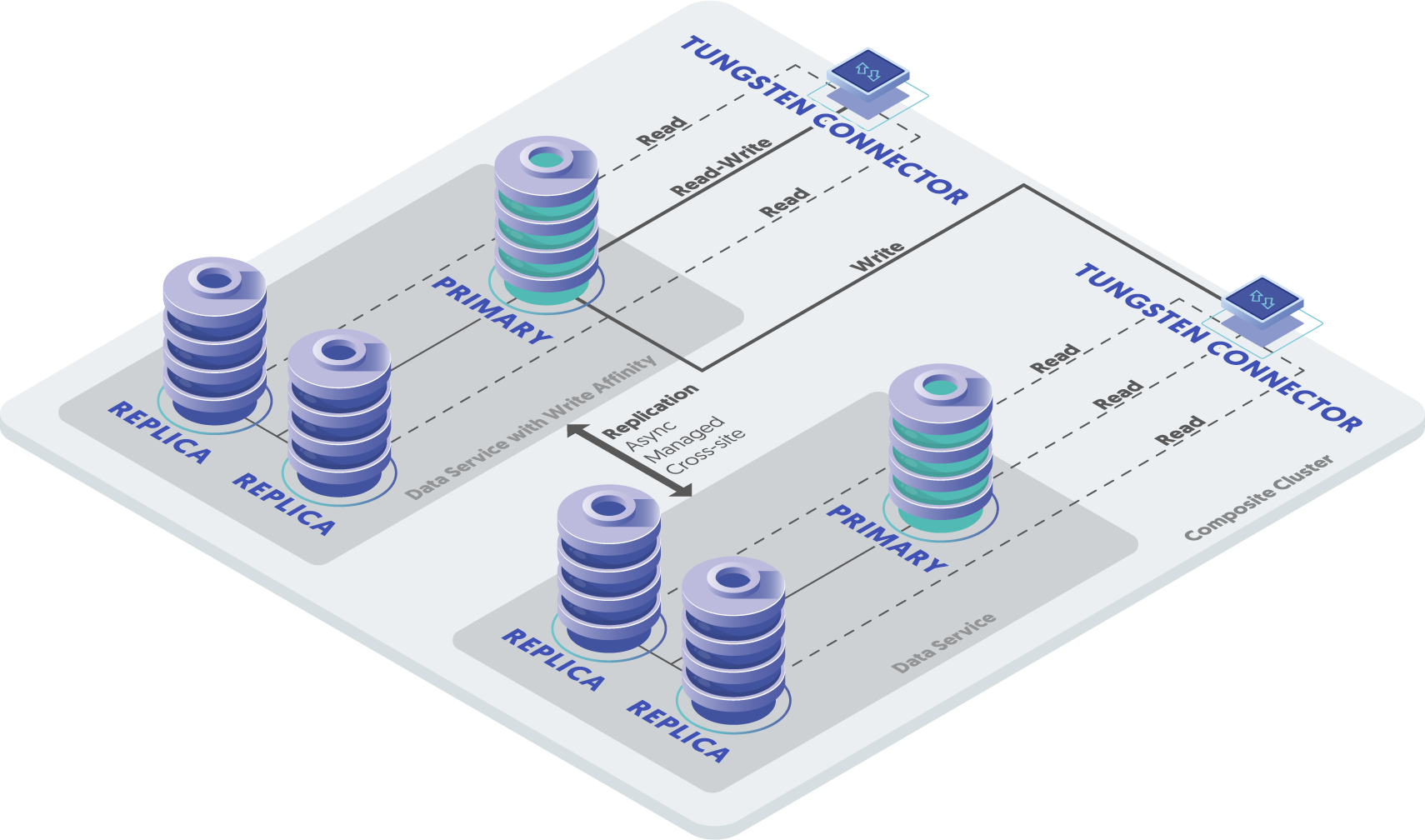
The ideal case would be a combination of site-level automatic failover for the highest level of availability, and a single write Primary for data simplicity, because Active-Active topologies are harder to manage successfully if the application was not designed to handle Active-Active. This topology would also support MIXED-based replication for lower overhead and better performance.
So with this introduction in mind, we present to you Tungsten Distributed Datasource Groups!
Distributed Datasource Groups: What?
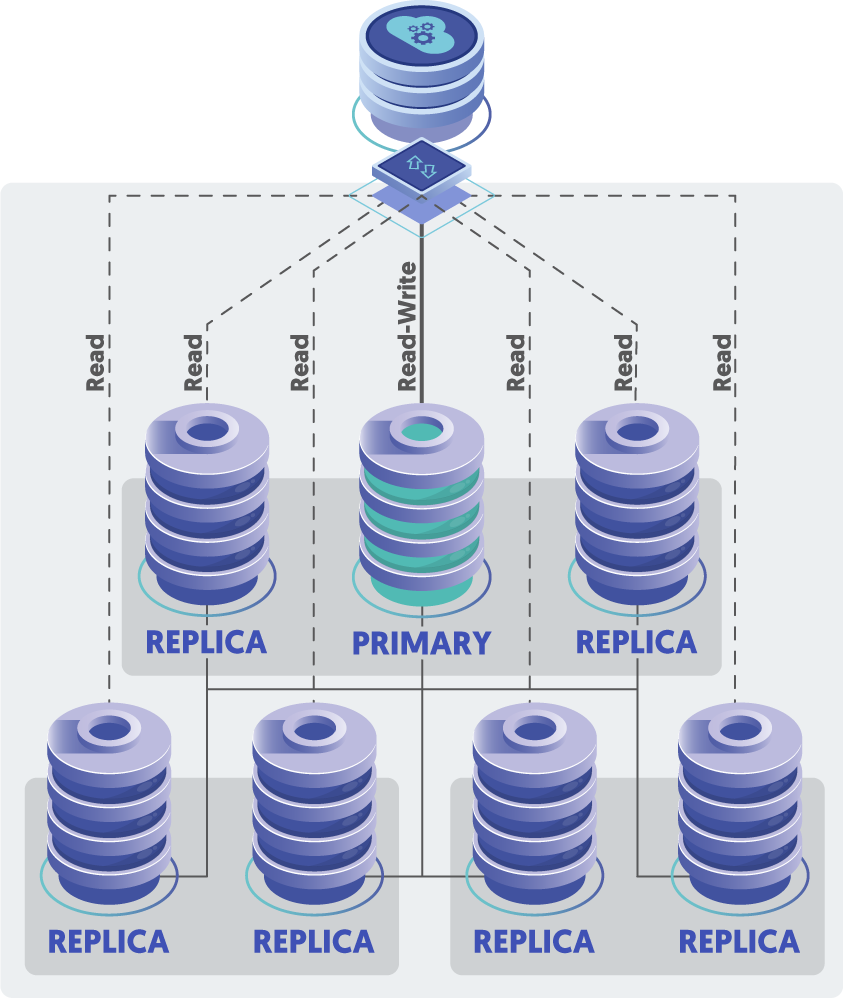
Tungsten Distributed Datasource Groups (DDG) are, at their core, a single Standalone cluster, with an odd number of nodes, as usual. In addition, every node in the cluster uses the same [serviceName], also as usual.
The key differences here are that:
- Each node in the cluster is assigned a Distributed Datasource Group ID (
DDG-ID). - Nodes with the same
DDG-IDwill act as if they are part of a separate cluster service, limiting failovers to nodes inside the group until there are no more failover candidates, at which time a node in a different group ID will be selected as the new primary during a failover.
This means that you would assign nodes in the same region or datacenter the same DDG-ID.
There is still only a single write Primary amongst all the nodes in all the regions, just like CAP.
Unlike CAP, if all nodes in the datacenter containing the Primary node were gone, a node in a different location would be promoted to Primary.
The networks between the datacenters or regions must be of low latency similar to LAN speed for this feature to work properly.
Also, the node in the same group with the most THL downloaded will be selected as the new Primary. If no node is available in the same group, the node with the most THL available is selected from a different group.
Distributed Datasource Groups: An Example
To illustrate the new topology, imagine a 5-node standard cluster spanning 3 datacenters with 2 nodes in DC-A, 2 nodes in DC-B and 1 node in DC-C.
Nodes in DC-A have DDG-ID of 100, nodes in DC-B have DDG-ID of 200, and nodes in DC-C have DDG-ID of 300.
Below are the failure scenarios and resulting actions:
- Primary fails
- Failover to any healthy Replica in the same Region/Datacenter (virtual ID group)
- Entire Region/Datacenter containing the Primary node fails
- Failover to any healthy Replica in a different Region/Datacenter (virtual ID group)
- Network partition between any two Regions/Datacenters
- No action, quorum is maintained by the majority of Managers.
- Application servers not in the Primary Datacenter will fail to connect
- Network partition between all Regions/Datacenters
- All nodes FAILSAFE/SHUNNED
- Any two Regions/Datacenters offline
- All nodes FAILSAFE/SHUNNED
Manual intervention to recover the cluster will be required any time the cluster is placed into the FAILSAFE/SHUNNED state.
As an additional example, if there was a network partition between DC-A and DC-B, with both DC-A and DC-B still seeing DC-C, the master will see itself in a majority group (3 of 5), and so no action/failover will happen.
Distributed Datasource Groups: How?
Configuration is very easy, just pick an integer group ID for each set of nodes you wish to group together, usually based upon location like region or datacenter, and add a new line to the [defaults] section of the /etc/tungsten/tungsten.ini file on every node, including Connector-only nodes, for example:
[defaults]
datasource-group-id=100
The new tpm configuration option datasource-group-id defines which Distributed Datasource Group that node belongs to. The new entry must be in the [defaults] section of the configuration.
Also, to disable DDG on that node, set datasource-group-id to zero like this:
[defaults]
datasource-group-id=0
Wrap-Up
In this post we explored the new Tungsten Distributed Datasource Groups feature, which allows for automatic database server failover between regions or datacenters while maintaining a single write primary for ease of application integration and low TCO.
Smooth sailing!

Comments
Add new comment