Overview
The Skinny
In this blog post, we will define what a split-brain scenario means in a MySQL database cluster. Then, we will explore how a Tungsten MySQL database cluster reacts to a split-brain situation and show how to recover from that situation.
Agenda
What's Here?
- Define the term "split-brain".
- Briefly explore how the Tungsten Manager works to monitor the cluster health and prevent data corruption in the event of a network partition.
- Examine how the Tungsten Connector works to route writes.
- Describe how a Tungsten MySQL database cluster reacts to a split-brain situation.
- Illustrate various testing and recovery procedures.
Split-Brain: Definition and Impact
Sounds Scary, and It Is!
A split-brain occurs when a MySQL database cluster, which normally has a single write primary, has two write-able primaries.
This means that some writes which should go to the "real" primary are sent to a different node which was promoted to write primary by mistake.
Once that happens, some writes exist on one primary and not the other, creating two broken primaries. Merging the two data sets is impossible, leading to a full restore, which is clearly NOT desirable.
We can say that a split-brain scenario is to be avoided by all means.
A situation like this is most often encountered when there is a network partition of some sort, especially with the nodes spread over multiple availability zones in a single region of a cloud deployment.
This would potentially result in all nodes being isolated, without a clear majority within the voting quorum.
A poorly-designed cluster could elect more than one primary under these conditions, leading to the split-brain scenario.
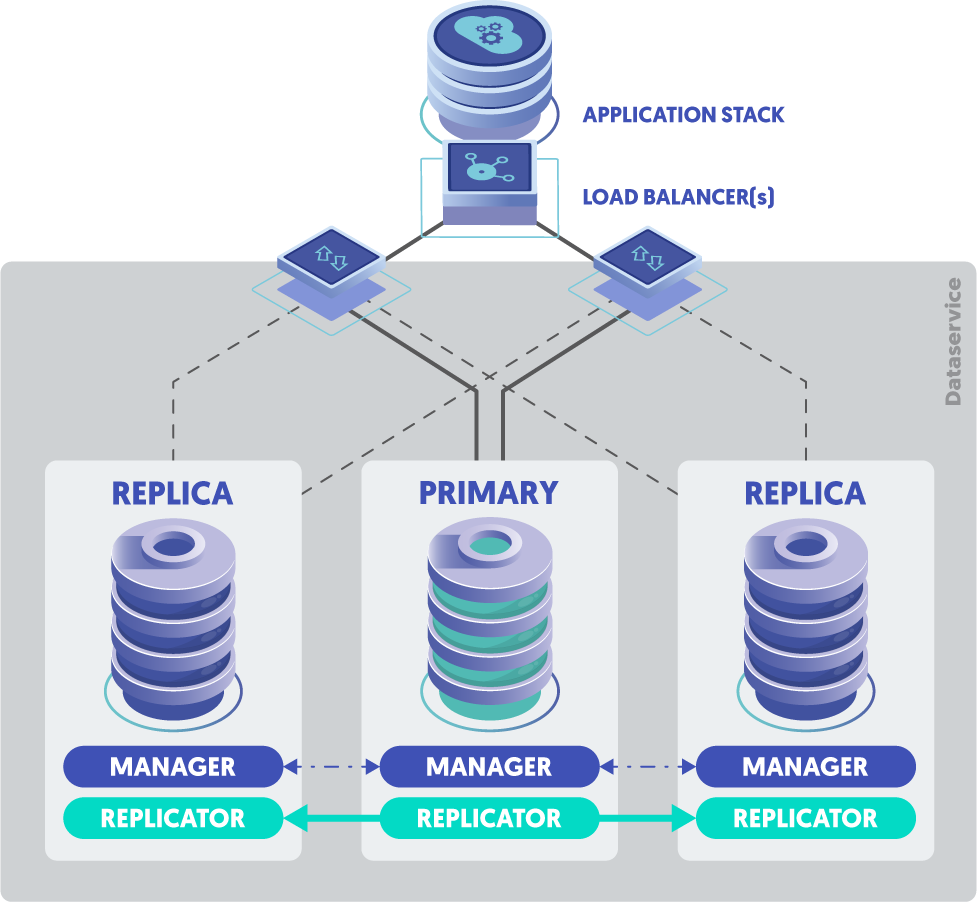
Tungsten Manager: A Primer
A Very Brief Summary
The Tungsten Manager health-checks the cluster nodes and the MySQL databases.
The Manager is responsible for initiating various failure states and helping to automate recovery efforts.
Each Manager communicates with the others via a Java JGroups group chat.
Additionally, the Connectors get status information from a chosen Manager as well...
Tungsten Connector: A Primer
Another Brief Summary
The Tungsten Connector is an intelligent MySQL database proxy located between the clients and the database servers, providing a single connection point, while routing queries to the database servers.
Simply put, the Connector is responsible for sending MySQL queries to the correct node in the cluster.
In the event of a failure, the Tungsten Connector can automatically route queries away from the failed server and towards servers that are still operating.
When the cluster Managers detect a failed primary (i.e. because the MySQL server port is no longer reachable), the Connectors are signaled, and client traffic is re-routed to the newly-elected Primary node.
Each Connector makes a TCP connection to any available Manager, then all command-and-control traffic uses that channel. The Manager never initiates a connection to the Connector.
When there is a state change (i.e. shun, welcome, failover, etc.), the Manager will communicate to the Connector over the existing channel.
The Connector will re-establish a channel to an available Manager if the Manager it is connected to is stopped or lost.
For more detailed information about how the Tungsten Connector works, please read our blog post, "Experience the Power of the Tungsten Connector".
Failsafe-Shun: Safety by Design
Protect the Data First and Foremost!
Since a network partition would potentially result in all nodes being isolated without a clear majority within the voting quorum, the default action of a Tungsten Cluster is to SHUN all of the nodes.
Shunning ALL of the nodes means that no client traffic is being processed by any node, both reads and writes are blocked.
When this happens, it is up to a human administrator to select the proper primary and recover the cluster.
The main thing that avoids split-brain in our clustering is that the Connector is connected to either:
- a Manager that is a member of a quorum, or
- a Manager that has all resources shunned.
In the first case, it's guaranteed to have a single primary. In the second case, it can't connect to anything until the Manager it is connected to is participating in a quorum.
Example Failure Testing Procedures
Use this procedure AT YOUR OWN RISK!
A failsafe-shun scenario can be forced.
For this example, we selected an easier way to demonstrate the Split-Brain scenario than doing an actual network partition. The end result will be the same because stopping the managers on the replicas is similar to having the network cut between the primary and the replicas. Either way, the primary can't communicate with the replica managers, breaking the Quorum.
Given a 3-node cluster east, with primary db1 and replicas db2/db3, simply stop the manager process on both replicas and wait about 60 seconds:
shell> manager stop
Stopping Tungsten Manager Service...
Stopped Tungsten Manager Service.
The Manager on the primary node db1 will restart itself after an appropriate timeout, and the entire cluster will then be in FAILSAFE-SHUN status.
Once you have verified that the cluster is in FAILSAFE-SHUN status, start the Managers on both slaves before proceeding with recovery:
shell> manager start
Starting Tungsten Manager Service...
Waiting for Tungsten Manager Service..........
running: PID:21911Example Recovery Procedures
First, examine the state of the dataservice and choose which datasource is the most up to date or canonical. For example, within the following example, each datasource has the same sequence number, so any datasource could potentially be used as the primary:
[LOGICAL] /east > ls
COORDINATOR
ROUTERS:
+----------------------------------------------------------------------------+
|connector@db1[18450](ONLINE, created=0, active=0) |
|connector@db2[8877](ONLINE, created=0, active=0) |
|connector@db3[8895](ONLINE, created=0, active=0) |
+----------------------------------------------------------------------------+
DATASOURCES:
+----------------------------------------------------------------------------+
|db1(master:SHUNNED(FAILSAFE AFTER Shunned by fail-safe procedure), |
|progress=17, THL latency=0.565) |
|STATUS [OK] [2013/11/04 04:39:28 PM GMT] |
+----------------------------------------------------------------------------+
| MANAGER(state=ONLINE) |
| REPLICATOR(role=master, state=ONLINE) |
| DATASERVER(state=ONLINE) |
| CONNECTIONS(created=0, active=0) |
+----------------------------------------------------------------------------+
+----------------------------------------------------------------------------+
|db2(slave:SHUNNED(FAILSAFE AFTER Shunned by fail-safe procedure), |
|progress=17, latency=1.003) |
|STATUS [OK] [2013/11/04 04:39:51 PM GMT] |
+----------------------------------------------------------------------------+
| MANAGER(state=ONLINE) |
| REPLICATOR(role=slave, master=db1, state=ONLINE) |
| DATASERVER(state=ONLINE) |
| CONNECTIONS(created=0, active=0) |
+----------------------------------------------------------------------------+
+----------------------------------------------------------------------------+
|db3(slave:SHUNNED(FAILSAFE AFTER Shunned by fail-safe procedure), |
|progress=17, latency=1.273) |
|STATUS [OK] [2013/10/26 06:30:26 PM BST] |
+----------------------------------------------------------------------------+
| MANAGER(state=ONLINE) |
| REPLICATOR(role=slave, master=db1, state=ONLINE) |
| DATASERVER(state=ONLINE) |
| CONNECTIONS(created=0, active=0) |
+----------------------------------------------------------------------------+Recover Master Using
Once you have selected the correct host, use cctrl to call the recover master using command specifying the full service name and hostname of the chosen datasource:
[LOGICAL] /east > recover master using east/db1
This command is generally meant to help in the recovery of a data service
that has data sources shunned due to a fail-safe shutdown of the service or
under other circumstances where you wish to force a specific data source to become
the primary. Be forewarned that if you do not exercise care when using this command
you may lose data permanently or otherwise make your data service unusable.
Do you want to continue? (y/n)> y
DATA SERVICE 'east' DOES NOT HAVE AN ACTIVE PRIMARY. CAN PROCEED WITH 'RECOVER USING'
VERIFYING THAT WE CAN CONNECT TO DATA SERVER 'db1'
DATA SERVER 'db1' IS NOW AVAILABLE FOR CONNECTIONS
DataSource 'db1' is now OFFLINE
DATASOURCE 'db1@east' IS NOW A MASTER
FOUND PHYSICAL DATASOURCE TO RECOVER: 'db2@east'
VERIFYING THAT WE CAN CONNECT TO DATA SERVER 'db2'
DATA SERVER 'db2' IS NOW AVAILABLE FOR CONNECTIONS
RECOVERING 'db2@east' TO A SLAVE USING 'db1@east' AS THE MASTER
DataSource 'db2' is now OFFLINE
RECOVERY OF DATA SERVICE 'east' SUCCEEDED
FOUND PHYSICAL DATASOURCE TO RECOVER: 'db3@east'
VERIFYING THAT WE CAN CONNECT TO DATA SERVER 'db3'
DATA SERVER 'db3' IS NOW AVAILABLE FOR CONNECTIONS
RECOVERING 'db3@east' TO A SLAVE USING 'db1@east' AS THE MASTER
DataSource 'db3' is now OFFLINE
RECOVERY OF DATA SERVICE 'east' SUCCEEDED
RECOVERED 2 DATA SOURCES IN SERVICE 'east'You will be prompted to ensure that you wish to choose the selected host as the new primary. cctrl then proceeds to set the new primary, and recover the remaining replicas.
If this operation fails, you can try the more manual process, next.
Welcome and Recover
A simple welcome attempt will fail:
[LOGICAL] /east > datasource db1 welcome
WARNING: This is an expert-level command:
Incorrect use may cause data corruption
or make the cluster unavailable.
Do you want to continue? (y/n)> y
ONLINE PRIMARY DATA SOURCE WAS NOT FOUND IN DATA SERVICE 'east'
To use the welcome command, the force mode must be enabled first:
[LOGICAL] /east > set force true
FORCE: true
[LOGICAL] /east > datasource db1 welcome
WARNING: This is an expert-level command:
Incorrect use may cause data corruption
or make the cluster unavailable.
Do you want to continue? (y/n)> y
DataSource 'db1' is now OFFLINE
Note the OFFLINE state as the result? In AUTOMATIC mode, the datasource will be set to ONLINE before you have the time to run the ls command and look at the cluster state:
[LOGICAL] /east > ls
COORDINATOR
ROUTERS:
+---------------------------------------------------------------------------------+
|connector@db1[9970](ONLINE, created=2, active=0) |
|connector@db2[10076](ONLINE, created=0, active=0) |
|connector@db3[11373](ONLINE, created=2, active=0) |
+---------------------------------------------------------------------------------+
DATASOURCES:
+---------------------------------------------------------------------------------+
|db1(master:ONLINE, progress=4, THL latency=0.667) |
|STATUS [OK] [2019/06/12 04:00:21 PM UTC] |
+---------------------------------------------------------------------------------+
| MANAGER(state=ONLINE) |
| REPLICATOR(role=master, state=ONLINE) |
| DATASERVER(state=ONLINE) |
| CONNECTIONS(created=1, active=0) |
+---------------------------------------------------------------------------------+
+---------------------------------------------------------------------------------+
|db2(slave:SHUNNED(FAILSAFE_SHUN), progress=4, latency=0.773) |
|STATUS [OK] [2019/06/12 03:47:42 PM UTC] |
+---------------------------------------------------------------------------------+
| MANAGER(state=ONLINE) |
| REPLICATOR(role=slave, master=db1, state=ONLINE) |
| DATASERVER(state=ONLINE) |
| CONNECTIONS(created=1, active=0) |
+---------------------------------------------------------------------------------+
+---------------------------------------------------------------------------------+
|db3(slave:SHUNNED(FAILSAFE_SHUN), progress=4, latency=0.738) |
|STATUS [OK] [2019/06/12 03:47:32 PM UTC] |
+---------------------------------------------------------------------------------+
| MANAGER(state=ONLINE) |
| REPLICATOR(role=slave, master=db1, state=ONLINE) |
| DATASERVER(state=ONLINE) |
| CONNECTIONS(created=2, active=0) |
+---------------------------------------------------------------------------------+Finally, recover the remaining replicas:
[LOGICAL] /east > recover
SET POLICY: AUTOMATIC => MAINTENANCE
FOUND PHYSICAL DATASOURCE TO RECOVER: 'db3@east'
VERIFYING THAT WE CAN CONNECT TO DATA SERVER 'db3'
Verified that DB server notification 'db3' is in state 'ONLINE'
DATA SERVER 'db3' IS NOW AVAILABLE FOR CONNECTIONS
The active primary in data service 'east' is 'db1@east'
RECOVERING 'db3@east' TO A SLAVE USING 'db1@east' AS THE MASTER
RECOVERY OF DATA SERVICE 'east' SUCCEEDED
FOUND PHYSICAL DATASOURCE TO RECOVER: 'db2@east'
VERIFYING THAT WE CAN CONNECT TO DATA SERVER 'db2'
Verified that DB server notification 'db2' is in state 'ONLINE'
DATA SERVER 'db2' IS NOW AVAILABLE FOR CONNECTIONS
The active primary in data service 'east' is 'db1@east'
RECOVERING 'db2@east' TO A SLAVE USING 'db1@east' AS THE MASTER
RECOVERY OF DATA SERVICE 'east' SUCCEEDED
REVERT POLICY: MAINTENANCE => AUTOMATIC
RECOVERED 2 DATA SOURCES IN SERVICE 'east'
[LOGICAL] /east > ls
COORDINATOR
ROUTERS:
+---------------------------------------------------------------------------------+
|connector@db1[9970](ONLINE, created=2, active=0) |
|connector@db2[10076](ONLINE, created=0, active=0) |
|connector@db3[11373](ONLINE, created=2, active=0) |
+---------------------------------------------------------------------------------+
DATASOURCES:
+---------------------------------------------------------------------------------+
|db1(master:ONLINE, progress=4, THL latency=0.667) |
|STATUS [OK] [2019/06/12 04:00:21 PM UTC] |
+---------------------------------------------------------------------------------+
| MANAGER(state=ONLINE) |
| REPLICATOR(role=master, state=ONLINE) |
| DATASERVER(state=ONLINE) |
| CONNECTIONS(created=1, active=0) |
+---------------------------------------------------------------------------------+
+---------------------------------------------------------------------------------+
|db2(slave:ONLINE, progress=4, latency=0.000) |
|STATUS [OK] [2019/06/12 04:06:36 PM UTC] |
+---------------------------------------------------------------------------------+
| MANAGER(state=ONLINE) |
| REPLICATOR(role=slave, master=db1, state=ONLINE) |
| DATASERVER(state=ONLINE) |
| CONNECTIONS(created=1, active=0) |
+---------------------------------------------------------------------------------+
+---------------------------------------------------------------------------------+
|db3(slave:ONLINE, progress=4, latency=0.000) |
|STATUS [OK] [2019/06/12 04:06:27 PM UTC] |
+---------------------------------------------------------------------------------+
| MANAGER(state=ONLINE) |
| REPLICATOR(role=slave, master=db1, state=ONLINE) |
| DATASERVER(state=ONLINE) |
| CONNECTIONS(created=2, active=0) |
+---------------------------------------------------------------------------------+Summary
The Wrap-Up
In this blog post, we defined what a split-brain scenario means, and explored how a Tungsten MySQL database cluster reacts to a split-brain situation.
To learn about Continuent solutions in general, check out our Products & Solutions page.
The Library
Please Read the Docs!
For more information about Tungsten Cluster recovery procedures, please visit our documentation.
Tungsten Clustering is the most flexible, performant global database layer available today - use it underlying your SaaS offering as a strong base upon which to grow your worldwide business!
Want to learn more or run a POC? Contact us.

Comments
Add new comment