When an application is an organization’s primary source of revenue, a lot goes into keeping the Production environment, aka “PROD,” running smoothly.
Why Multiple Environments?
There may be more or fewer “environments” with different purposes, but Production is the “final performance” where all the work comes together. Examples of other environments include:
- Development environment / DEV - allows developers to test their changes in an isolated environment without fear of breaking critical systems.
- Staging environment - allows large scale simulation and testing of roll back procedures if something goes wrong, preventing these issues from ever making it into production; being able to test new procedures to deploy to production, etc.
In fact, that’s why multiple environments exist - to make sure that the final version, delivered in Production, runs smoothly. Read on to make sure your labor is not in vain!
Please note that my perspective is born out of my experience with Production database services because that’s the space my company works in, but the “essentials” may apply to any part of PROD.
On that note, who am I to be talking about business-critical Production environments? This blog comes from my observations working in this world for many years. The Continuent team provides software and support for a number of global customers who use our solutions with open source databases (MySQL, MariaDB, or Percona MySQL) to keep business-critical Production environments running smoothly.
Production Environment - Essentials
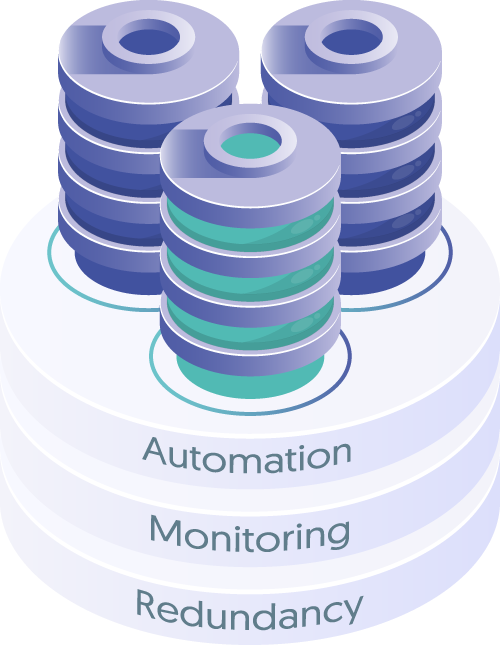
Now that we’ve established that the goal of the Production environment is to deliver a stellar final act - continuously and reliably - let’s dive into three things that can help with that.
-
Redundancy
Having backups is one thing, but having real-time updated replicas available to serve your application when your Primary server is down, planned or unplanned, is a different ballgame. In Production you need both. Replication is important to keep the Production environment going despite hardware failures and maintenance - but not just one replica; there should ideally be an odd total number of nodes to prevent split brain scenarios, and obviously, more nodes means more redundancy. With replication, many questions arise. How do you cut over from one server to another without dropping connections? How do you make sure the data on the new Primary is up-to-date, and how do you keep track of the last replicated row and cut over the replication flow, so that the new Primary is now the new Writer, and the old Primary is a new Replica? This can get especially tricky when you have load balancing or read/write splitting, since there must be some level of awareness and orchestration to redirect reads and writes to new nodes based on new roles. If you’re interested, please see this blog to learn about the difference between replication and clustering.
-
Monitoring
The maintenance of a system must involve a process for observation. There are different levels of observability. As a baseline you must have a regular status check of high-level operations. The more granular the metrics, the more clear the picture you can have of your operations to prevent problems ahead of time. A proper system for observability includes collecting and visualizing data, as well as an alerting system for when human attention is required. Tools like Prometheus, Grafana, Pagerduty, and others make it easy.
But there is also a layer of monitoring that’s not meant for human eyes. Within any Production environment, there should be internal, automated monitoring as well. For the clustered database layer in our customers’ Production environments, there is the Tungsten Manager that monitors and orchestrates cluster operations. It would be impossible for a human to manage that system of observability because its work involves highly systematic, logical tasks, and it runs 24/7/365. This brings us to the third Production environment essential, which is Automation; but one last note about Production monitoring - for certain managed clustering topologies, Tungsten Manager is aware of the state of components across the global deployment - so if a cluster goes down on the other side of the world, the system is aware and able to adjust and respond appropriately. This highlights how with geo-scale Production environments, the need for intelligent monitoring and automation is a requirement, not just a nice-to-have.
-
Automation
Production operations usually involve more repetitive work than Dev and other environments; and as you know, manual labor introduces the chance of human error. Automation has its Pros and Cons, and while consistency is one of the Pros, sometimes you need a human to make decisions when a situation is more complex. Automating the manual work out of running Production environments can be done so that when manual intervention is involved, it’s only because it’s required by design - and it simply involves a human as decision-maker, not task-executor.
As shown by a recent AWS outage, caused by “unexpected behavior from automated systems,” it’s a double-edged sword that should be used mindfully.
There’s a lot more that goes into it but if you think about Redundancy, Monitoring, and Automation as fundamentals, you’re probably on the path for successful, cost-effective business-critical Production operations.
After lots of refinement and time taken in the proper environments, you can be guaranteed a good night’s sleep because you’ve done everything you can to ensure a reliable and continuous final act. To take advantage of these three Production essentials and take ownership of your MySQL and MariaDB Production operations, check out our clustering solutions.

Comments
Add new comment