MySQL clustering versus replication? One allows you to sleep at night...and the other will keep you up if they’re alike!
MySQL replication is the process of moving data in real-time to other MySQL database servers so as to create real-time-updated replicas. Creating replicas may be known as “scaling out” or “horizontally,” (versus “scaling up” or “vertically” by buying bigger servers). But there is a big difference between replication and clustering; you may have multiple MySQL replicas, but without added layers of intelligence and orchestration from a MySQL database proxy and integrated cluster manager, you do not have a cluster. Replication alone does not meet the requirements of organizations with mission-critical or business-critical applications.
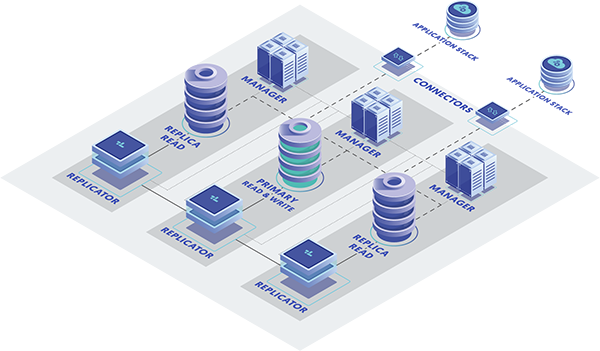
When we talk about MySQL clustering, we mean combining several MySQL database servers (with up-to-date copies of live data) into a single entity, either as a single cluster or geo-distributed cluster of clusters. There are many good reasons enterprises do this, including:
- Availability - fault-tolerance, avoid downtime
- Load Balancing - performance, and efficiency
- Scalability - ability to grow indefinitely
- Geographic distribution - eg. bring database closer to end-users
- Modular design - flexibility, easy to make changes and with no application changes or downtime
Tungsten Clustering allows you to add and remove nodes from the database layer without causing a service disruption. You can upgrade MySQL software (and everything else on the database node) with zero downtime. Clustering your database layer is seen as the de-facto standard best practice for ensuring high availability, disaster recovery, and performance from your geographically distributed MySQL database layer.
Replication is naturally involved in clustering, but in the case of Continuent, replication can also be used on its own for both homogenous (MySQL to MySQL) and heterogeneous (MySQL to various other database targets) replication purposes. This might be where the confusion comes from - Tungsten Replicator is a unique replication engine for MySQL, MariaDB, and Percona Server that not only serves high-performance apps and mission-critical apps, but also Business Intelligence (BI), Reporting, and Big Data Analytics functions. Feel free to check out our webinar about advantages of replication versus ETL if you’re interested to learn more about this.
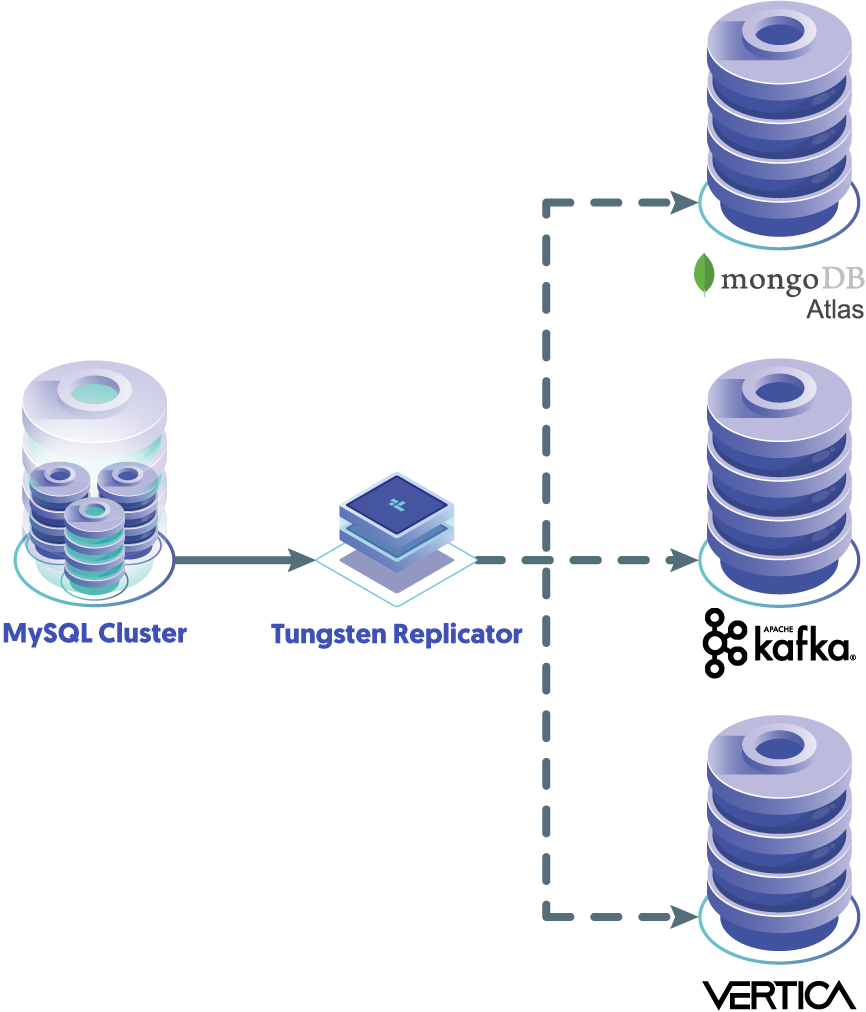
Many of our customers use both Tungsten Clustering and Tungsten Replicator as it simplifies data engineering systems to have one, seamless integrated system for operational and organizational data streams.
How is this possible? It has to do with the way the Tungsten Replication engine works. It converts data changes into an easily-distributed, flexible format we call THL, or “Transaction History Log.” THL is easy to move data in real-time with little resource cost or latency over a network - and, it’s a format can quickly and easily be converted to a variety of database targets.
As many organizations trend toward using multiple databases specialized for various functions, transmuting data to different data stores has become an important and usually costly process to set up and maintain. That’s why we make it easy and inexpensive to replicate data out of highly available MySQL clusters; so your team can focus on more revenue-generating functions. In fact, Tungsten Replicator includes capabilities that AWS considers “managed replication,” but we’ll get into that in more detail in another blog!
I hope you learned something about the difference between MySQL replication and clustering. Feel free to follow us on Linkedin or Twitter to learn more!

Comments
Add new comment